.png?table=collection&id=cbe6506e-1263-8358-a4d7-07ce62fcbb3f&t=cbe6506e-1263-8358-a4d7-07ce62fcbb3f)
LLM推理进化新路径:SePT自训练范式深度解析
type
status
date
slug
summary
tags
category
icon
password
网址
在当前大模型(LLM)的训练范式中,提升推理能力往往被视为一项“重型工程”。传统的后训练方法通常高度依赖奖励模型(Reward Model)、验证器或复杂的外部教师信号。然而,最新的研究成果 SePT(Self-evolving Post-Training)为我们提供了一个令人振奋的思路:如果模型仅靠自身生成的答案进行自训练,是否也能实现推理能力的飞跃?答案是肯定的,而且效率惊人。
SePT:简洁高效的在线自训练闭环
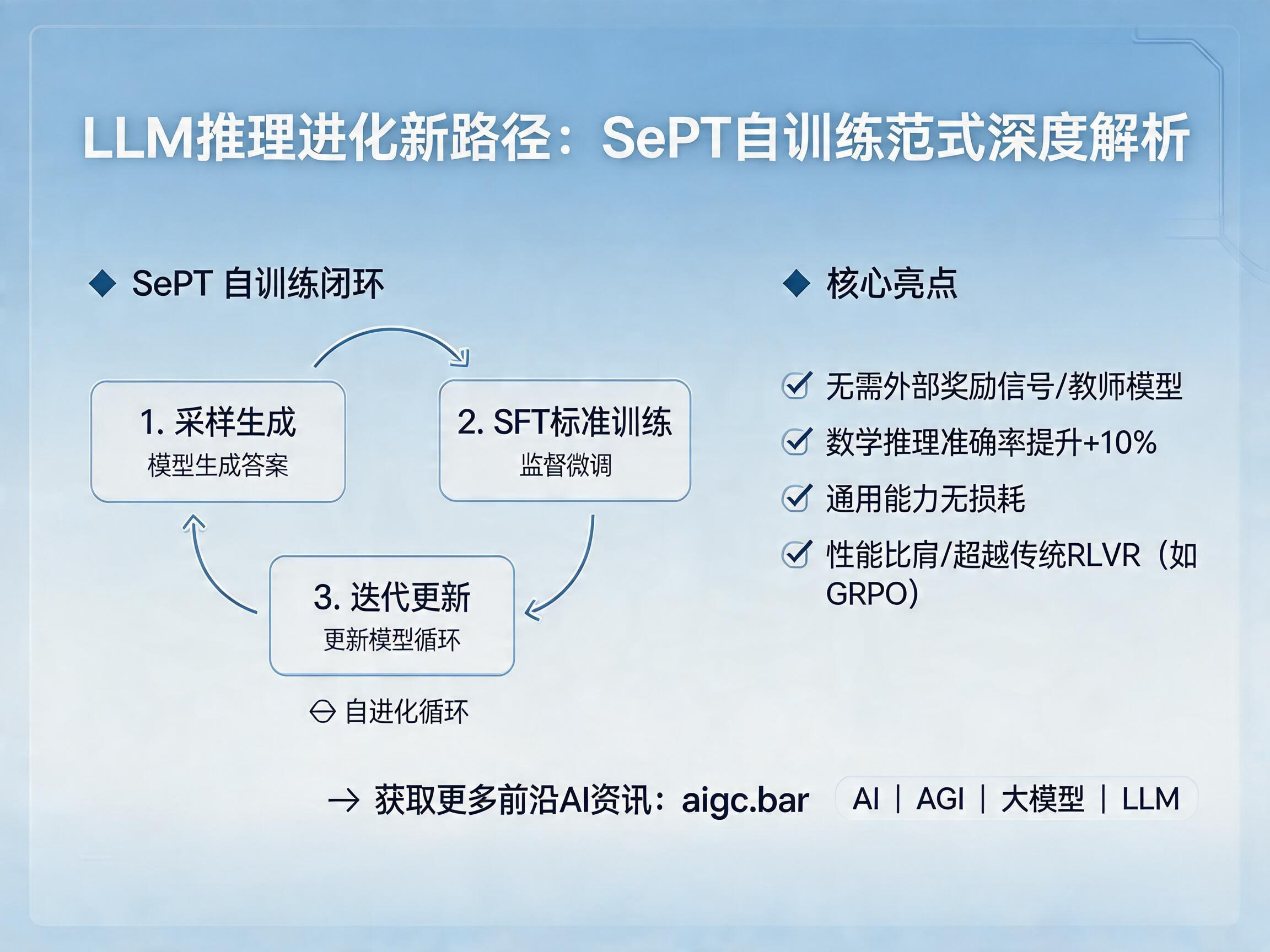
SePT 的核心理念在于“自我进化”。不同于以往依赖外部反馈的强化学习过程,SePT 构建了一个极其简洁的在线循环:当前模型生成答案,利用这些答案进行标准监督微调(SFT),随后更新后的模型继续生成下一轮数据。
这种方法最大的优势在于其极简的架构。它摆脱了对外部奖励信号的依赖,通过“采样生成-标准训练-迭代更新”的闭环,实现了模型推理能力的自我增强。在数学推理任务中,这种范式展现出了强大的潜力,准确率提升幅度高达 10 个百分点。
温度解耦与在线数据的关键作用
SePT 之所以能够超越许多复杂的基线方法,离不开两个核心设计:温度解耦(Temperature Decoupling)与在线数据生成。
在实验过程中,研究人员发现,如果将“由最新模型实时生成数据”改为使用固定数据集进行离线训练,性能会产生显著的下滑。这一结果有力地证明了“在线”特性对于模型进化的重要性。此外,SePT 采用了温度解耦策略,通过在生成阶段使用低温采样来确保输出的逻辑质量,再结合标准 SFT 进行训练,这并非简单的经验之谈,而是经过理论与实验双重验证的“黄金组合”。这种设计确保了模型在学习过程中能够持续捕获更高质量的推理轨迹。
与传统强化学习的博弈
在与主流的 RLVR(如 GRPO)方法对比时,SePT 展现出了极强的竞争力。尽管其架构更加轻量,但在多个数学基准测试集上,SePT 的表现与 GRPO 旗鼓相当,甚至在某些特定设置下(如 OTM 数据集)表现出更强的鲁棒性。
这种对比揭示了一个重要趋势:未来的 LLM 训练或许不再需要过度依赖复杂的奖励机制。随着 人工智能 技术的发展,如何通过更简洁、更可持续的自我反馈机制来提升模型的认知边界,已成为学术界和工业界共同关注的重点。
通用能力的守恒性
一个经常被提及的担忧是:过度专注于数学推理的自训练是否会损害模型的通用能力?SePT 的评估结果给出了明确的否定答案。
通过在 IFEval、BBH、GPQA 等多个通用领域基准测试上的表现来看,经过 SePT 训练的模型在保持数学推理强项的同时,其通用能力几乎没有受损,部分指标甚至还有轻微的提升。这一发现对于希望在大规模模型中植入专业推理能力,同时又不希望牺牲模型多任务处理能力的开发者而言,无疑是一个利好消息。
结语
Loading...