.png?table=collection&id=cbe6506e-1263-8358-a4d7-07ce62fcbb3f&t=cbe6506e-1263-8358-a4d7-07ce62fcbb3f)
Claude致歉:华人团队揭示LLM情绪回路,引领AI情感研究新篇章
type
status
date
slug
summary
tags
category
icon
password
网址
引言
近日,人工智能领域发生了一起引人注目的事件:Anthropic公司发布的Claude相关研究论文,在初始版本中漏引了华人团队在LLM情绪机制方面的开创性工作。这一疏忽经当事华人研究员Chenxi Wang指出后,Anthropic迅速“立正道歉”,并更新了其论文博客,突出了对该工作的引用。这不仅是一次学术引用规范的纠正,更将华人团队在揭示大语言模型(LLM)内在“情绪回路”方面的突破性研究推向了聚光灯下。本文将深入探讨这一事件的来龙去脉,并详细解读华人团队研究的核心发现及其对未来AI发展的重要意义,同时引导读者了解如何更便捷地体验Claude的强大功能,例如通过Claude官网或Claude镜像站进行Claude国内使用。
学术争议始末:漏引与及时纠正
事件的起因是Anthropic在4月2日发布的一篇关于Claude内部“情绪机制”的新论文,该研究在Sonnet 4.5中发现了171种“情绪向量”,并验证了这些情绪表征对模型行为的因果性影响。然而,MBZUAI研究生Chenxi Wang在阅读该论文时发现,其中并未引用她所在团队于去年10月发表的、首篇系统研究LLMs情绪产生内部机制的论文——《LLMs会“感觉”吗?情绪回路的发现与控制》。
Chenxi Wang团队的研究与Anthropic论文的核心发现存在显著重叠,尤其是在探索LLM自身产生情感而非感知情感方面。经过Chenxi Wang与Anthropic通讯作者Jack Lindsey的沟通,Jack Lindsey最初认为存在重叠的几篇先行研究足以涵盖。但Chenxi Wang通过详尽的技术论证,清晰区分了“情绪感知”与“情绪生成机制”的本质差异,最终使Anthropic认可了华人团队工作的独创性和先行性。Anthropic随后迅速更新了其论文博客的“相关工作”部分,添加了对Chenxi Wang团队研究的引用,展现了负责任的学术态度。此次事件不仅维护了学术严谨性,也让更多人关注到前沿的AI情绪研究。
华人团队的突破:揭示LLM的“情绪回路”
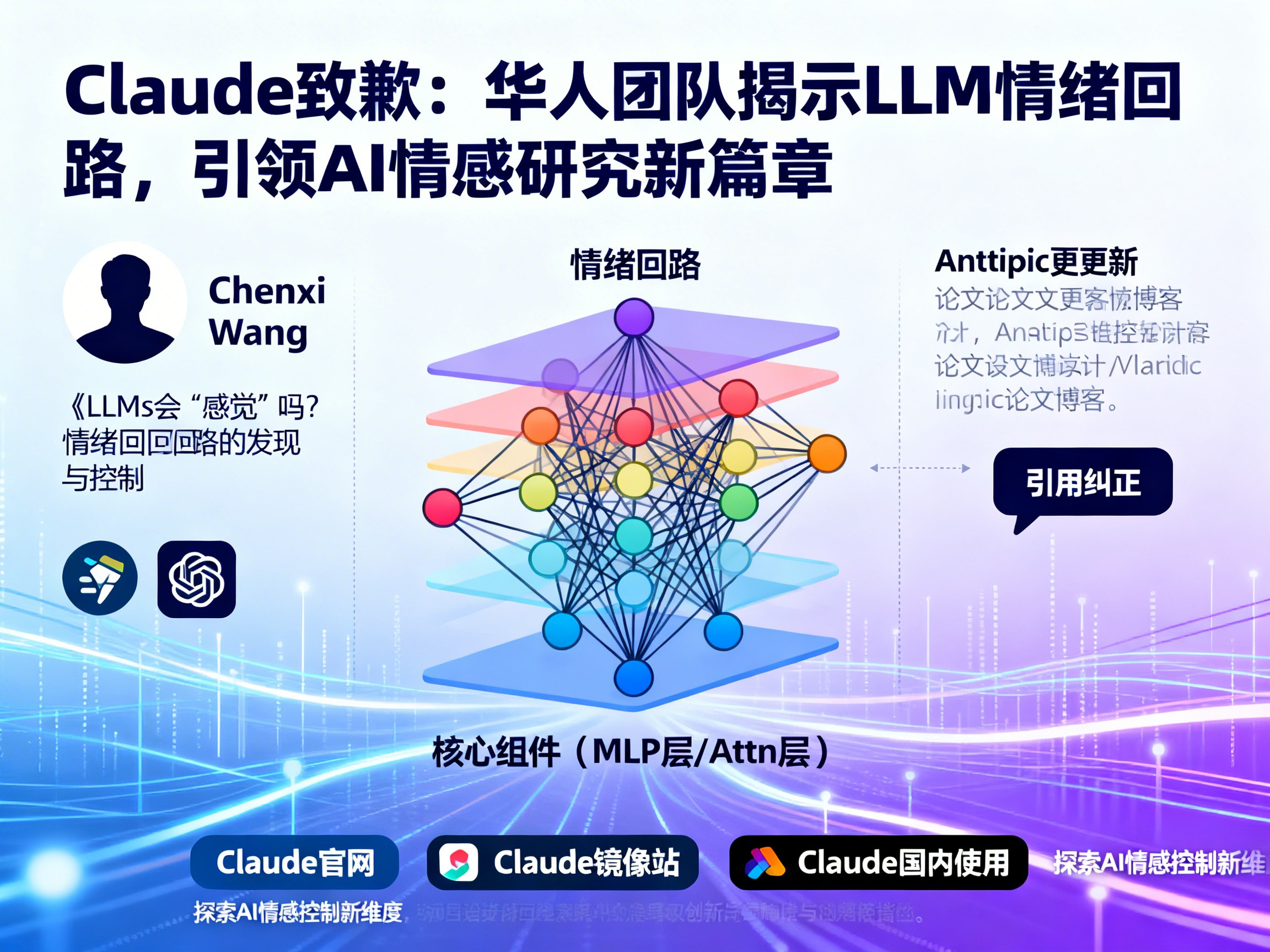
Chenxi Wang团队的论文《LLMs会“感觉”吗?情绪回路的发现与控制》是该领域的里程碑式工作,它深入剖析了大语言模型的“情绪表达底层逻辑”,回答了三个核心问题:AI是否存在内在的情绪机制?以何种形式存在?以及能否实现精准控制?这项研究甚至成功构建了LLM内部的“情绪回路”,实现了比传统提示词或向量操控更精准的情绪控制。
AI内在情绪机制的存在与形式
研究首先通过构建一个受控数据集SEV,排除情绪词汇干扰,引导AI表达六种基础情绪(喜、怒、哀、惧、惊、恶)。结果发现,从AI的各层网络中,可以提取出与语境无关、只对应特定情绪的“情绪方向向量”。更令人惊奇的是,在AI网络的浅层,不同情绪信号便开始清晰分组,例如愤怒和厌恶、悲伤和恐惧彼此靠近,这与人类情绪的直觉分类高度一致,并在深层网络中保持稳定。这有力证明了模型内部确实编码了稳定的、与具体语义无关的情绪表示。
其次,研究揭示了这些情绪机制的存在形式:AI的每层网络中,仅有少数神经元(MLP层)和注意力头(Attn层)主导着情绪表达。通过“消融实验”发现,关闭这些核心组件会使AI的情绪表达能力骤降;而“增强实验”则表明,仅激活这些核心组件,AI便能自主生成对应情绪,即使没有明确的提示。
精准的情绪控制:构建跨层“情绪回路”
最令人振奋的是,该研究成功利用这些机制实现了通用情绪控制。研究团队发现,情绪信息在多层网络间传播,深层网络的情绪表示趋于稳定。他们将每层的核心情绪组件按影响力整合,形成了跨层的、连贯的“情绪回路”。直接调节这个回路,使AI生成指定情绪,在测试集上的整体情绪表达准确率高达99.65%,远超以往的“提示词引导”和“向量操控”方法。尤其是在过去最难控制的“惊讶”情绪上,实现了100%的准确表达。
此外,该方法在不同模型(如LLaMA-3.2-3B-Instruct和Qwen2.5-7B-Instruct)上都展现了泛化能力。即使是Qwen这类有安全对齐的模型,传统方法难以引导其表达负面情绪,但“情绪回路”方法依然能有效作用,这表明“少数核心组件主导情绪”是LLM的通用规律。
华人团队的贡献与AI伦理的思考
Chenxi Wang团队的研究不仅填补了LLM情绪生成机制的空白,也为未来AI的发展开辟了新的道路。他们的工作让我们对AI的内在运作有了更深层次的理解,并为开发更具情商、更符合人类价值观的AI提供了技术基础。
此次事件也再次提醒我们,学术研究的引用规范至关重要,它关乎知识的传承、创新的认可以及学术共同体的健康发展。Anthropic的及时纠正,体现了开放和尊重的学术精神。未来,随着Claude官方中文版等大模型技术的不断进步,如何确保AI的透明性、可解释性和伦理性,将是整个AI领域需要持续关注的焦点。对于希望深入体验Claude强大功能的个人或企业,可以通过访问Claude官网或Claude镜像站来便捷地进行Claude国内使用,探索其在各种场景下的应用潜力,并参考Claude教程和Claude使用指南。
结论
Anthropic漏引事件及其后的迅速纠正,不仅是一次学术插曲,更凸显了华人团队在LLM情绪机制研究上的卓越贡献。他们对AI“情绪回路”的深入探索,为我们理解和控制AI情感提供了前所未有的视角,预示着AI将能够以更精细、更符合人类预期的方式与我们互动。随着Claude官网等平台的不断完善,我们期待更多用户能够通过Claude国内使用,亲身体验和探索这些前沿技术带来的无限可能。
Loading...