.png?table=collection&id=1e16e373-c263-81c6-a9df-000bd9c77bef&t=1e16e373-c263-81c6-a9df-000bd9c77bef)
深入解析Claude Skills容量上限:2026年单体智能体开发指南
type
status
date
slug
summary
tags
category
icon
password
网址
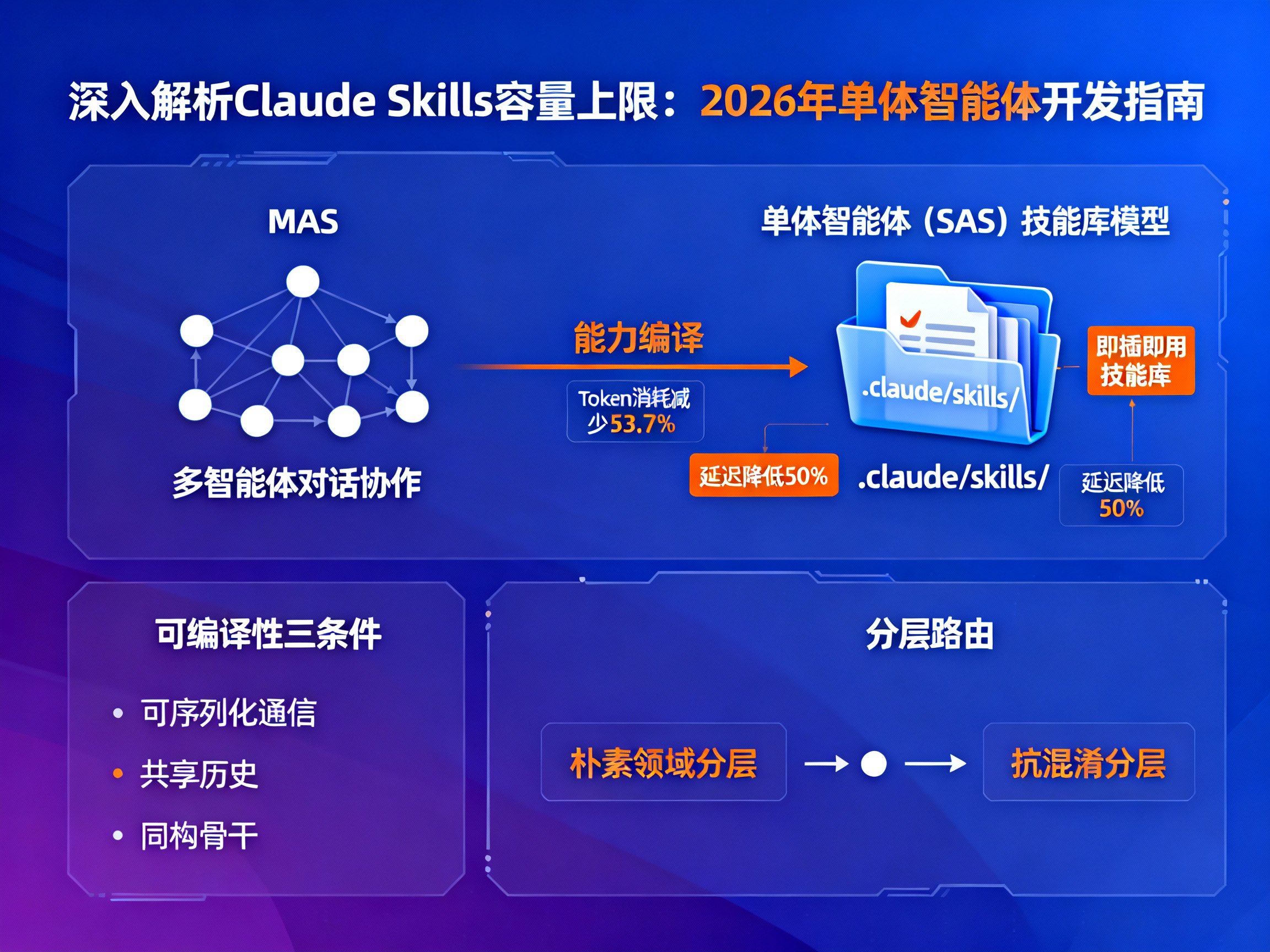
在当今的AI开发领域,特别是随着 Claude官方 推出的各项新功能,开发者们正经历一场从繁杂的多智能体编排(MAS)向高效的“即插即用”单体智能体(SAS)的范式转移。当我们打开电脑,看着
.claude/skills/ 文件夹中日益增多的Markdown文件,一种“全能助手”的错觉油然而生。将数百个技能挂载给一个Agent,似乎就能解决所有问题,同时还能让API账单和延迟大幅降低。然而,来自UCB、Vector Institute和CIFAR的最新研究为这种盲目的扩张泼了一盆冷水。研究指出,就像CPU存在缓存未命中一样,大语言模型(LLM)的技能检索也存在物理极限。本文将基于这项前沿研究,深入探讨 Claude国内使用 场景下Agent Skills的“扩容墙”,并为2026年的智能体开发提供一套科学的避坑指南。如果您正在寻找 Claude教程 或希望优化您的 Claude使用指南,这篇文章将是您的必读之选。
从协作到编译:单体智能体的效率诱惑
在深入探讨局限性之前,我们必须理解为什么行业风向会从多智能体转向单体智能体。过去,为了解决复杂任务,我们习惯于构建Coder、Reviewer和Manager等多个Agent进行“对话”。这种方式虽然有效,但伴随着巨大的计算开销:上下文冗余、网络通信延迟以及昂贵的Token消耗。
UCB的研究提出了一种“能力编译”(Capability Compilation)的视角。这意味着,原本独立的多智能体系统可以被“编译”成一个单体系统的技能库。实验数据显示,在GSM8K和HotpotQA等基准测试中,经过编译后的单体智能体不仅保持了高准确率,还实现了惊人的效率提升:Token消耗平均减少53.7%,延迟降低近50%。对于通过 Claude镜像站 或API进行高频调用的开发者而言,这意味着成本的直接减半。
编译的硬边界:何时不能使用Skills?
尽管单体Skills架构诱人,但并非所有系统都能被“降维打击”。研究者定义了“可编译性”的三个严格条件,一旦违反,您就必须坚持使用多智能体架构,否则系统将面临逻辑崩塌:
- 可序列化通信:交互流程必须是线性的或循环的。如果您的业务逻辑依赖于多个智能体在同一时刻独立思考并产生分歧(并行冲突),单体模型无法在同一上下文中模拟这种“精神分裂”。
- 共享历史:所有角色的输出必须依赖全局可见的历史记录。如果Agent A拥有Agent B绝对不可见的“私有秘密”,编译会导致信息泄露。
- 同构骨干:所有原始智能体必须使用能力相当的底层模型。如果绘图依赖特定模型而写作依赖 Claude官方中文版 级别的模型,它们就不能简单合并。
智能体的认知过载:50-100个技能的“相变”
既然单体效率高,我们可以无限添加技能吗?答案是否定的。研究发现,随着技能库规模的线性增长,Agent的清醒程度会经历一次非线性的“相变”。
实验表明,当技能数量突破某个临界值(通常在50到100之间),模型的准确率会突然断崖式下跌。这与人类的“有限理性”高度相似。导致这种崩溃的根本原因并非仅仅是数量,而是语义混淆(Semantic Confusability)。
如果您的技能库中同时存在“计算总和(Calculate Sum)”和“计算合计(Compute Total)”这样语义高度相似的技能,哪怕只有两个,准确率也会暴跌。这提示我们在 Claude国内如何使用 高级功能时,必须精简技能描述。
解决方案:回归人类智慧的分层路由
面对海量技能,如何避免模型“CPU过载”?论文提出了基于人类认知心理学的解决方案——分层路由。
- 朴素领域分层:类似于电脑文件夹管理,将技能按“数学域”、“写作域”物理切割。Router先选领域,再加载具体技能。
- 抗混淆分层:这是一种更高级的策略。主动将“长得像”的技能归类到一个簇(Cluster)中。第一步粗粒度路由选择语义正交的簇(确保高准确率),第二步在簇内进行细粒度消歧。
实验证明,这种“分而治之”的策略能有效突破单体智能体的认知极限。
2026年开发者的实战黄金法则
基于上述研究,为了在 Claude官方 架构或类似环境中构建稳健的Agent,我们总结了以下实战建议:
- 监控技能库规模:时刻警惕技能数量,不要盲目堆砌。
- 最小化语义混淆:在添加新Skill前进行“语义审计”。如果新旧技能太像,请合并它们。
- 投资于描述符优化:实验证明,Prompt的具体执行策略长短不影响选择,但YAML头部的
description至关重要。请花时间打磨那些独特、区分度高的描述符。
- 为任务匹配模型:在技能库庞大或混淆度高时,不要吝啬成本,使用如 Claude 3.5 Sonnet 或更高级别的强模型,它们具有更强的抗混淆能力。您可以通过 Claude镜像站 体验不同模型的能力差异。
- 考虑替代架构:如果分层路由也无法解决问题,说明您触碰了单体架构的物理极限,请回退到多智能体架构。
结论
这篇来自UCB的研究实质上是一份《Agent Skills架构扩容指南》。它证实了模块化技能的巨大潜力,但也无情地揭示了模型的认知边界。对于广大开发者而言,现在的任务不是编写更多的Skills,而是进行重构(Refactoring)。
在2026年的AI开发浪潮中,学会“做减法”和“分层管理”将是构建高效智能体的关键。无论您是通过 Claude官网 直连还是使用 Claude国内使用 的优化方案,遵循这些科学原则,都能让您的AI应用在复杂性面前保持清醒与高效。
想要深入体验 Claude官方中文版 的强大能力,或寻找更稳定的 Claude镜像站 服务以测试您的Agent Skills架构,请务必访问 https://claude.aigc.bar。那里有您构建下一代智能体所需的一切资源。
Loading...