.png?table=collection&id=cbe6506e-1263-8358-a4d7-07ce62fcbb3f&t=cbe6506e-1263-8358-a4d7-07ce62fcbb3f)
智源FlagOS赋能:DeepSeek-V4实现跨芯适配的三大核心技术突破
type
status
date
slug
summary
tags
category
icon
password
网址
在当前人工智能领域,大模型能力的快速演进与硬件算力生态的碎片化,成为了制约技术普惠的两大核心矛盾。近日,由智源研究院牵头研发的众智 FlagOS 系统软件栈,成功完成了对 DeepSeek-V4-Flash 旗舰模型的 Day0 适配,实现了包括华为昇腾、海光、沐曦、摩尔线程等在内的八款以上主流 AI 芯片的无缝部署。这一突破不仅展示了国产算力生态的潜力,更为解决“模型-硬件”适配难题提供了全新的技术范式。更多前沿的 AI 动态与 LLM 技术趋势,欢迎关注 AI资讯门户。
跨芯适配的里程碑意义
DeepSeek-V4 系列模型作为当前行业内领先的 大模型,其复杂的混合专家(MoE)架构与超长上下文处理能力,对底层系统软件提出了极高要求。过去,由于不同芯片厂商的硬件架构及算子库差异,模型从研发到在特定硬件上上线往往需要数周甚至数月的工程适配。FlagOS 此次实现的 Day0 适配,本质上是将复杂的“M×N”硬件适配问题,通过统一的软件栈转化为“M+N”的标准化流程,极大加速了尖端算法在国产算力平台上的落地速度。
三大核心技术突破解析
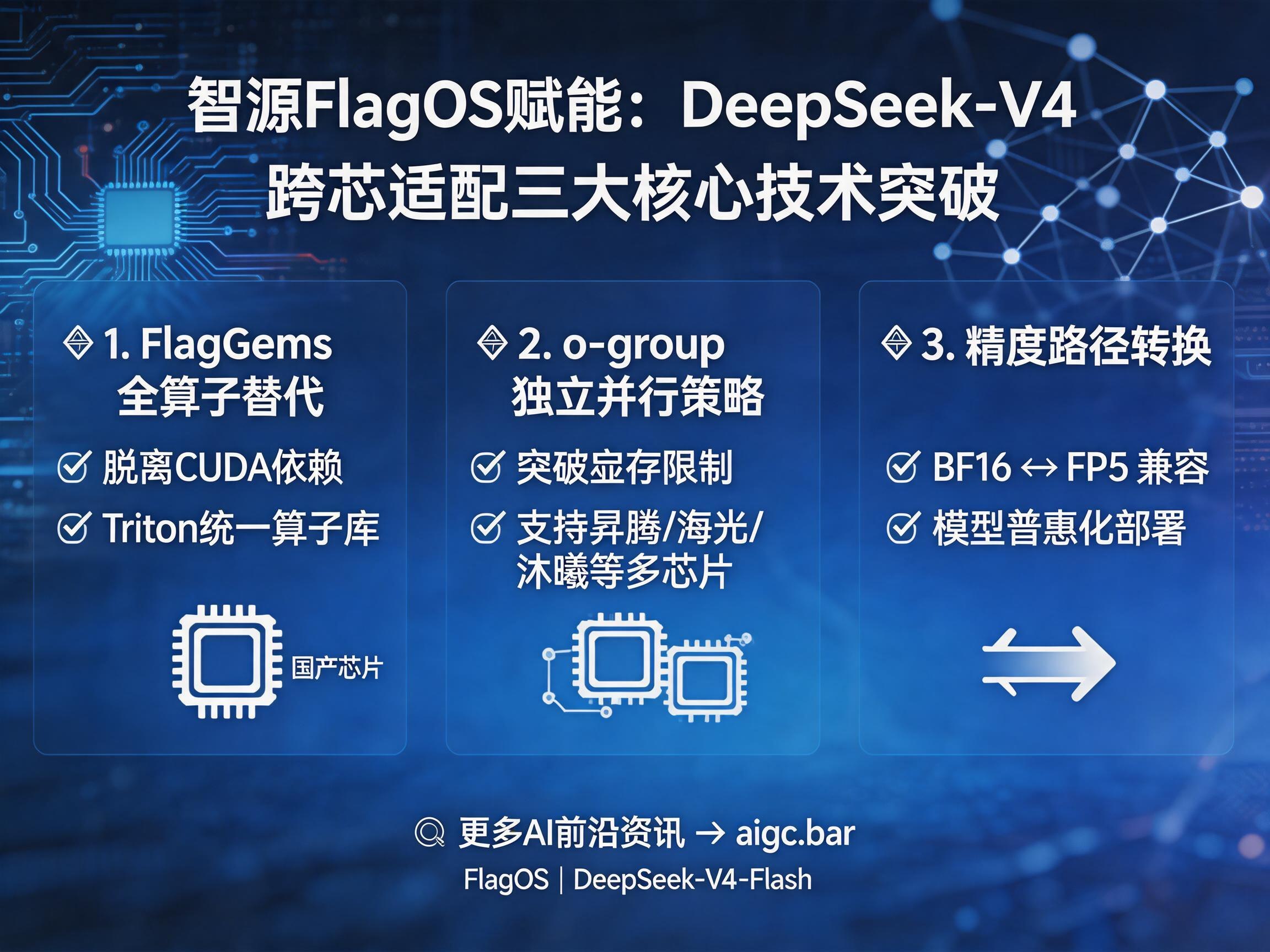
为了实现 DeepSeek-V4-Flash 在多款架构迥异的芯片上稳定高效运行,FlagOS 技术团队攻克了三大关键技术难点:
FlagGems 全算子替代:彻底告别 CUDA 依赖
FlagGems 作为全球最大的 Triton 单一算子库,在此次适配中起到了决定性作用。它通过基于 Triton/Triton-TLE 语言对推理链路中的核心算子(如 MoE 路由、Attention 计算等)进行重构,实现了对 cuDNN/cuBLAS 等 NVIDIA 私有库的脱离。这意味着开发者无需针对每款新芯片进行重复的工程适配,只要芯片后端支持 Triton,即可享受高性能计算支持。
o-group 独立并行策略:解锁显存限制
针对 DeepSeek-V4-Flash 在分组输出投影(Grouped Output Projection)上的设计,FlagOS 创新性地引入了独立张量并行策略。传统张量并行常受限于单卡显存规模,而该策略通过为 o-group 构建独立的通信组,使得模型能够突破单机 8 卡的并行限制,将适用范围从仅限高显存的旗舰卡,扩展至 32GB/64GB 显存的主流国产芯片,极大地提升了硬件利用率。
精度路径转换:打通 BF16 与 FP8 生态
针对 DeepSeek-V4 原生采用的 FP4+FP8 混合精度在国产芯片上的兼容性难题,FlagOS 完成了从 FP4 到 BF16 的完整精度路径重构。通过权重反量化与计算路径的重新适配,确保了在缺乏 FP4 硬件支持的设备上,模型依然能保持核心能力指标的对齐。这一举措让 DeepSeek-V4 不再是少数“顶级昂贵硬件”的专属,真正迈向了普惠化。
开发者视角:从极简部署到生态共建
FlagOS 不仅仅是一个技术栈,更是一个开放的开发者生态。对于希望快速部署该模型的团队,FlagOS 提供了包含 Docker 镜像、统一算子库及 vLLM-plugin-FL 插件在内的一站式解决方案。
如果你是 人工智能 开发领域的从业者,或者正在寻找大模型落地的工程路径,可以访问 aigc.bar 获取更多关于 AI变现、提示词 优化以及 大模型API 开发的实战指南。FlagOS 的全栈开源策略,旨在将技术主动权完全交还给开发者,无论你是初学者还是资深系统工程师,都能在社区中通过提交代码、优化算子或反馈场景需求,共同推动 AGI 时代的算力基础设施建设。
结论与展望
智源 FlagOS 对 DeepSeek-V4 的适配,不仅是一次技术层面的成功,更标志着国产 AI 算力生态正在从“孤岛化”走向“协同化”。随着异构算力协同技术的不断成熟,未来将有更多领先的 openai 级别模型能够快速在多元化的国产硬件上“开箱即用”。对于广大开发者而言,拥抱统一的系统软件栈,将是降低开发成本、提升模型落地效果的关键一步。更多深度内容,请持续关注 AI日报。
Loading...