.png?table=collection&id=cbe6506e-1263-8358-a4d7-07ce62fcbb3f&t=cbe6506e-1263-8358-a4d7-07ce62fcbb3f)
MSRA发布RepoGenesis:AI从零构建代码仓库的里程碑
type
status
date
slug
summary
tags
category
icon
password
网址
在人工智能快速发展的今天,大模型写代码的能力早已不是新闻。然而,现有的代码生成基准(如HumanEval或ClassEval)大多停留在函数级或片段级的补丁编写。真正的软件工程挑战在于从零开始:读懂一份需求文档,搭建出符合规范的目录结构、处理复杂的依赖关系、确保跨文件接口的一致性,并最终实现可部署。微软亚洲研究院(MSRA)发表于ACL 2026的研究工作——RepoGenesis,正是为了解决这一工程痛点而生。
从代码片段到完整仓库的跨越
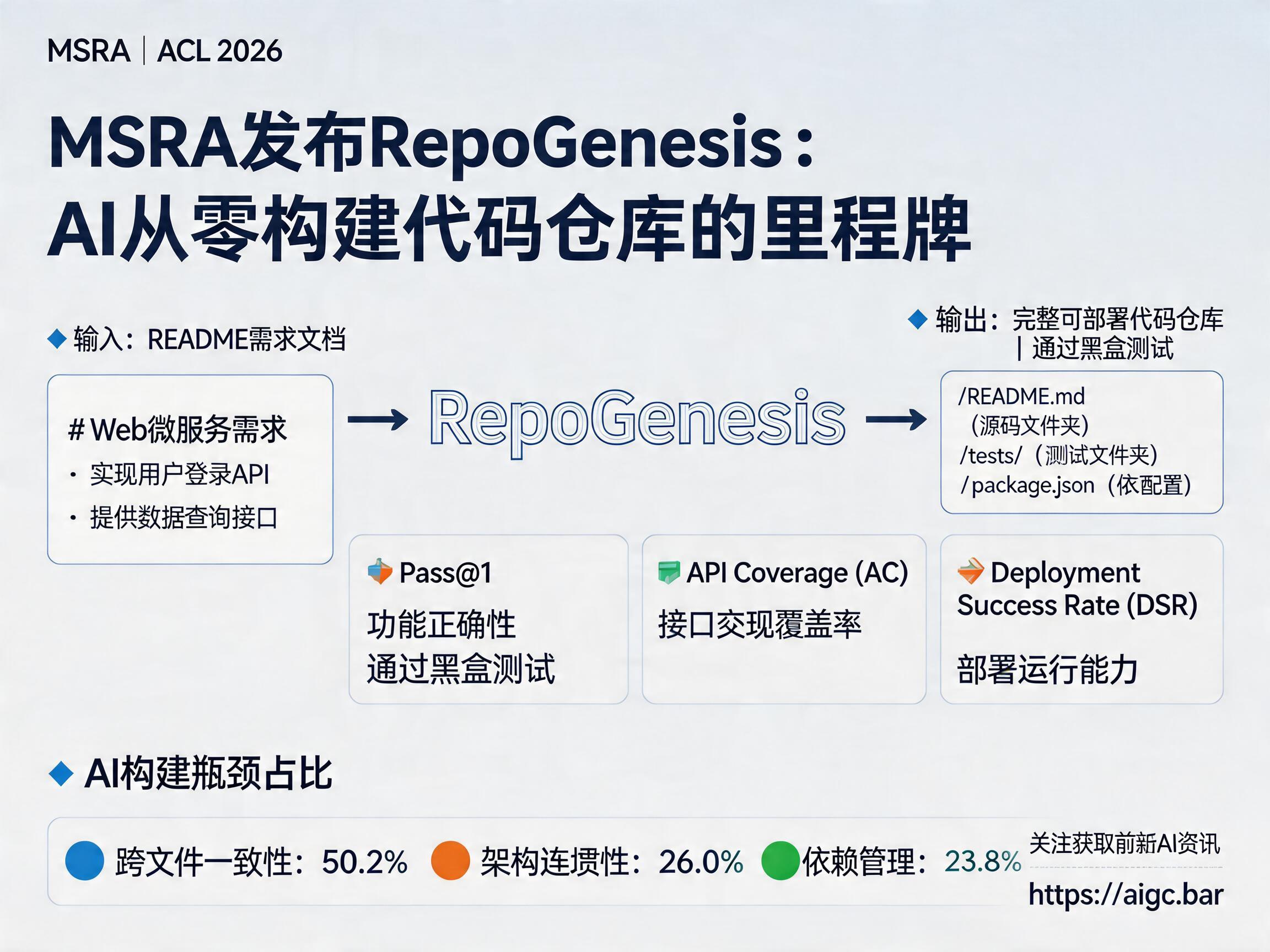
RepoGenesis是首个面向多语言、仓库级、端到端Web微服务生成的基准。它不再满足于简单的代码补全,而是将考点直接搬到了真实世界的开发流水线上。该项目的核心逻辑非常清晰:输入一份README式的需求文档,要求AI生成整套代码仓库,且必须通过黑盒测试并能成功部署。
这种设计将AI的能力边界从“局部优化”推向了“全局构建”。在AI资讯和LLM领域中,RepoGenesis的出现标志着代码生成基准测试开始回归工程本质,即不仅要写得出来,更要跑得起来。
全方位的工程化评测矩阵
如果只关注准确率,往往会掩盖AI在工程实践中的虚假繁荣。RepoGenesis引入了三个核心指标,全面评估生成质量:
- Pass@1:衡量功能是否正确,能否通过严苛的黑盒测试。
- API Coverage (AC):评估需求文档中的接口实现覆盖率。
- Deployment Success Rate (DSR):验证生成的仓库是否具备真正的部署运行能力。
通过这三根柱子,研究人员清晰地揭示了一个事实:即使AI能够覆盖大部分接口,甚至在某些情况下部署成功率达到100%,但在逻辑自洽和架构连贯性上仍有明显短板。这种深度评测不仅是技术指标的对比,更是对大模型工程落地能力的真实拷问。
为什么AI在复杂仓库构建中依然会“翻车”
研究发现,AI在构建复杂仓库时主要面临三大瓶颈:跨文件一致性问题(占比约50.2%)、架构连贯性(26.0%)以及依赖管理(23.8%)。
这意味着,现有的模型在处理单一文件时游刃有余,但一旦涉及多个文件之间的接口调用、错误处理一致性以及复杂的构建链路(尤其是在Java等强类型语言中),就会出现逻辑断层。这为未来的大模型训练提供了明确的方向:不仅仅是喂入更多的代码,更要通过高质量的成功轨迹蒸馏,提升模型对工程逻辑的理解。
展望:GenesisAgent与代码生成的未来
为了验证基准的有效性,研究团队推出了GenesisAgent,通过轨迹蒸馏生成的微调样本,在模型性能上取得了显著提升。这证明了RepoGenesis不仅是一个考场,更是一个能够反哺模型进化的优质数据源。
随着人工智能技术的演进,我们正见证从“辅助编程”向“自动工程”的转变。对于关注AGI和人工智能发展的开发者而言,理解这些底层的评测逻辑至关重要。如果你想获取更多关于大模型、Prompt优化及AI变现的深度资讯,建议关注 AI资讯门户,这里汇集了最前沿的AI动态与技术解析。
结论:
RepoGenesis的意义在于它将“从文档到仓库”这一过程变得可复现、可对比。它提醒我们,距离完全自动化的软件工程还有一段路要走,但通过这种贴近工程的硬评测,我们正逐步扫清模型落地过程中的盲区。在未来,能够处理跨文件逻辑、具备强架构设计能力的模型,将成为企业开发效率提升的关键驱动力。
Loading...