.png?table=collection&id=cbe6506e-1263-8358-a4d7-07ce62fcbb3f&t=cbe6506e-1263-8358-a4d7-07ce62fcbb3f)
AI时代的底层革命:为何Braintrust选择自建Brainstore数据库?
type
status
date
slug
summary
tags
category
icon
password
网址
在当今的 AI 行业中,我们往往被复杂的模型架构和精妙的 提示词 (Prompt) 设计所吸引,却容易忽略支撑这一切的底层基础设施。近期,AI可观测性公司Braintrust的创始人Ankur Goyal发布的一篇技术长文引发了业界的广泛讨论。他直言不讳地指出:“AI可观测性本质上是一个数据库问题。”为了解决现有数据库在处理AI工作负载时的崩溃与性能瓶颈,Braintrust投入两年时间自建了专用数据库——Brainstore。这一案例不仅是技术上的大胆尝试,更折射出 大模型 (LLM) 时代下基础设施层正在发生的剧烈变革。
AI工作负载引发的数据质变
传统的Web应用监控通常处理的是结构化、轻量级的日志数据,而AI系统产生的数据在体量和复杂性上完全不同。一个生产环境的AI智能体每秒可能产生10万个观测数据单元(span),且单条记录往往包含完整的上下文、推理链路、工具调用结果及长对话历史。
这意味着数据的体积比传统监控大了两到三个数量级。传统的数据库设计初衷是管理图书馆式的卡片目录,而现在却被要求存储整个城市的实时监控录像。这种量级的增长不是简单的堆叠,而是质的飞跃,直接导致了现有技术栈的失效。
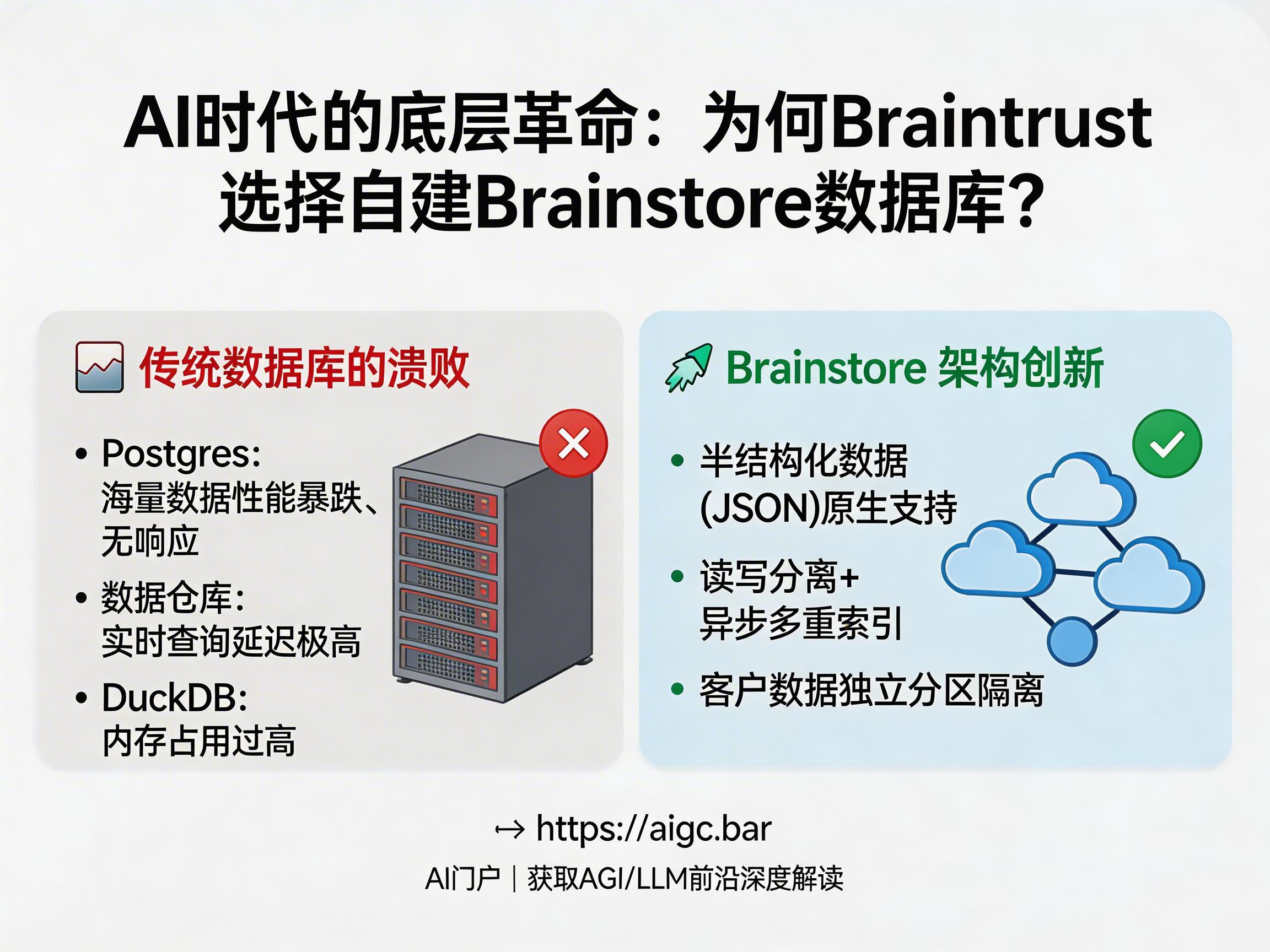
传统数据库架构的全面溃败
Braintrust在自建数据库之前,曾尝试过“开源数据仓库 + Postgres + DuckDB”的组合架构。然而,在AI的高并发、乱序写入以及双模式读取(即既需要精准定位单条记录,又需要大规模聚合分析)的夹击下,这套架构迅速暴露了短板:
- Postgres在处理海量半结构化数据和复杂的索引更新时,性能表现急剧下降,甚至出现无响应。
- 数据仓库虽然能存储海量数据,但在实时更新和快速查询上存在巨大的延迟。
- 浏览器端的DuckDB在处理大规模AI日志时,内存占用过高,且难以实现跨平台的统一查询语法。
当系统的核心体验直接受限于基础设施的性能时,开发者不得不寻找更优的解决方案。更多关于AI技术趋势的深度解读,欢迎访问 AI门户 (https://aigc.bar) 获取最新资讯。
Brainstore的架构创新:数据即一等公民
Brainstore的核心设计逻辑在于“回归本质”。它摒弃了依赖本地磁盘的传统做法,转而将所有数据存在对象存储上,并针对AI数据的特性进行了深度优化:
- 半结构化数据原生化:Brainstore不再强行将复杂的JSON数据拆解为列,而是将其视为一等公民,支持在嵌套结构上直接进行高效查询与过滤。
- 读写分离与异步索引:通过预写日志(WAL)保证写入吞吐,后台持续进行压缩和索引(包括倒排、行、列、向量等多重索引),确保查询性能与实时性的平衡。
- 客户数据独立分区:通过物理隔离,避免了全局数据集过大带来的性能衰减,这对于企业级的私有化部署至关重要。
自建 vs 外购:AI时代的权衡
Braintrust自建数据库的决策,是“少量集中的大型技术赌注”。在当前的 人工智能 领域,很多公司面临着同样的难题:现有的开源方案虽然丰富,但往往在特定场景下无法完全满足要求。
这一举动向行业传递了一个信号:当现有的技术轮子无法承载AI时代的业务逻辑时,自建基础设施或许是获得核心竞争力的唯一途径。正如SpaceX自建引擎一样,Braintrust通过Brainstore不仅优化了产品体验,更建立起了一道深厚的护城河。
结语:AI工程化的深水区
Brainstore的出现,标志着 AI 工程化已经进入了深水区。从模型调优到数据存储,每一个环节的极致优化都决定了产品的迭代速度。对于致力于 AI变现 和产品落地的团队而言,关注底层数据库与基础设施的演进,与关注 ChatGPT、Claude 等前沿大模型同样重要。
我们正处在一个基础设施被重塑的时代。谁能更快地解决AI数据处理的“脏活累活”,谁就能在未来的竞争中占据主动权。想要获取更多关于 AGI 和 LLM 的前沿动态,请持续关注我们的 AI资讯平台 (https://aigc.bar),我们将为您带来更多深度的技术观察与趋势分析。
Loading...