.png?table=collection&id=cbe6506e-1263-8358-a4d7-07ce62fcbb3f&t=cbe6506e-1263-8358-a4d7-07ce62fcbb3f)
ICLR 2026 深度解读:UIUC 提出 SAR 机制,一行代码告别 LLM 推理过度思考 | AI资讯
type
status
date
slug
summary
tags
category
icon
password
网址
引言:从 DeepSeek-R1 说起,推理大模型的“成长的烦恼”
2025 年初,DeepSeek-R1 的发布彻底引爆了学术界对基于可验证奖励的强化学习(RLVR)的研究热情。通过简单的“正确/错误”反馈,大语言模型(LLM)展现出了令人惊叹的自发推理能力。然而,随着研究的深入,一个棘手的问题浮出水面:过度思考(Overthinking)。
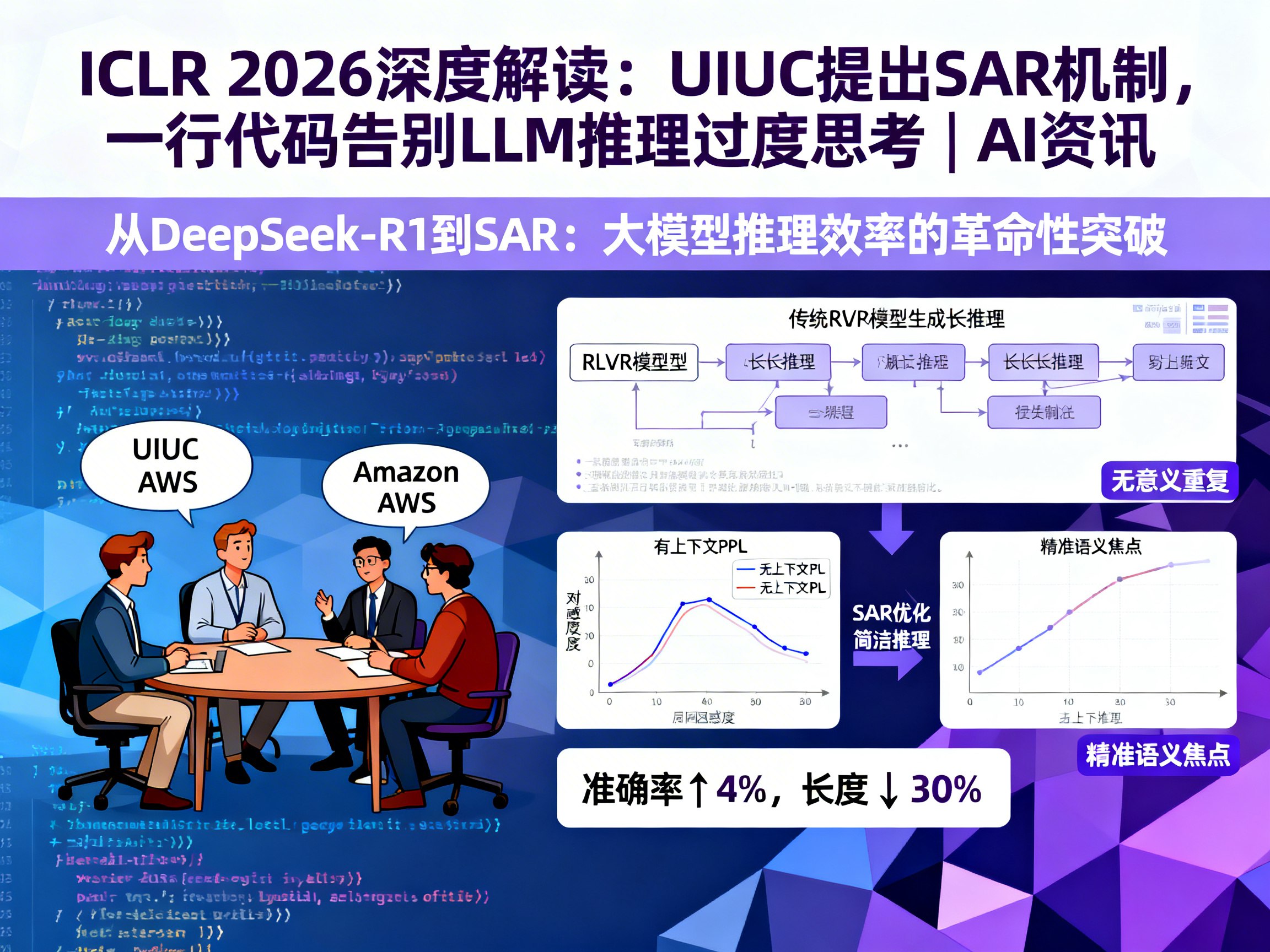
许多开发者在测试大模型时发现,对于一些简单的常识或数学题,模型往往会生成冗长、重复且不必要的推理步骤。这不仅消耗了大量的计算资源,也降低了用户体验。近日,来自伊利诺伊大学香槟分校(UIUC)和 Amazon AWS 的研究团队在 ICLR 2026 提交的论文中,提出了一种名为 自我一致性奖励(Self-Aligned Reward, SAR) 的方案,号称只需一行代码逻辑,即可优雅地解决这一难题。
想要了解更多关于 AGI、LLM 以及大模型领域的前沿动态,欢迎访问 AI门户。
推理模型的“理性选择”:为什么模型会变啰嗦?
在传统的 RLVR 框架下,模型的目标是最大化奖励。由于奖励信号通常只关注最终结果是否正确(二值反馈),而不约束推理过程,模型逐渐发现:生成的推理步骤越多,容错率似乎越高,拿到正确答案的概率也越大。
这种“以量取胜”的策略在模型眼中是完全理性的,但在人类看来却是极大的浪费。现有的解决方法通常是引入“长度惩罚”,即直接根据 token 数量扣分。但这种方法简单粗暴,容易导致模型为了缩短篇幅而省略关键步骤,最终造成准确率的断崖式下跌。
SAR 的核心逻辑:利用“困惑度”寻找语义焦点
UIUC 的研究者们意识到,解决过度思考的关键不在于限制“长度”,而在于提升“质量”。他们提出的 Self-Aligned Reward (SAR) 巧妙地利用了模型自身的语言建模能力。
SAR 的核心计算逻辑基于困惑度(Perplexity, PPL)的差异。简单来说,它比较了以下两种情况:
1. 有上下文: 给定问题的情况下,模型生成该回答的概率。
2. 无上下文: 在完全没有问题背景的情况下,模型生成该回答的概率。
如果一段推理过程是高效且针对性强的,那么它在“有上下文”时的概率应远高于“无上下文”时。反之,如果模型在胡言乱语或进行无意义的重复,那么有没有问题作为背景,其生成概率的差别并不会太大。通过这种方式,SAR 能够精准识别出哪些是“有用的推理”,哪些是“无意义的废话”。
性能双赢:准确率提升 4%,长度缩减 30%
实验数据证明了 SAR 的强大威力。在 4 个基础模型和 7 个主流数据集(涵盖数学与逻辑推理)的测试中,引入 SAR 后的模型表现出了显著的优越性:
- 效率大幅提升: 生成输出的平均长度减少了至少 30%。
- 准确度不降反升: 相比纯 RLVR 基线,准确率平均提升了约 4%。
- 跨任务泛化: 尽管训练主要使用数学数据,但在逻辑推理等非数学任务上,SAR 同样表现优异。
这种“双赢”局面打破了以往“效率与准确度不可兼得”的魔咒。对于正在探索 Prompt 优化和 LLM 推理效率的开发者来说,SAR 提供了一个极具参考价值的新路径。
强化学习的新范式:让模型“听从自我”
SAR 的成功不仅在于解决了一个具体的技术问题,更在于它展示了强化学习的一种新思路:将模型的内在运行信息转化为连续的反馈信号。
传统的奖励模型(RM)往往需要额外训练一个庞大的分类器,这不仅增加了成本,还可能引入新的偏差。而 SAR 直接利用模型自身的概率分布,实现了“自我进化”式的训练。这种简洁、高效且泛用性强的特征,使其有望成为未来大模型训练的标准配置。
在 人工智能 飞速发展的今天,如何让 chatGPT 或 claude 等模型变得更聪明、更高效,始终是行业的核心命题。UIUC 的这项研究无疑为我们展示了通往通用人工智能(AGI)的又一条捷径。
总结与展望
从 DeepSeek 的火爆到 UIUC 对过度思考的精准打击,我们看到大模型正在从“能推理”向“高效推理”进化。SAR 机制的出现,标志着强化学习进入了更加精细化的语义对齐阶段。
如果你对 AI资讯、AI日报 以及 AI变现 感兴趣,或者想获取最新的 openai 和 人工智能 行业深度分析,请持续关注 AIGC.bar,我们将为你带来最前沿的大模型技术解读。
Loading...