.png?table=collection&id=cbe6506e-1263-8358-a4d7-07ce62fcbb3f&t=cbe6506e-1263-8358-a4d7-07ce62fcbb3f)
深度解析语义高亮:解决AI Agent与搜索噪音的终极方案
type
status
date
slug
summary
tags
category
icon
password
网址
在人工智能飞速发展的今天,无论是企业级的RAG(检索增强生成)系统,还是能够自主执行任务的AI Agent,它们的核心能力都建立在对海量信息的检索与理解之上。然而,随着数据维度的爆炸式增长,我们面临的一个核心痛点不再是“找不到信息”,而是“如何在海量结果中快速定位有效信息”。
长期以来,搜索系统依赖的“高亮”功能,就像是我们学生时代手中的荧光笔,帮助我们一眼看到重点。但在大模型(LLM)和复杂语义检索的时代,传统的关键词匹配技术已经显得捉襟见肘。本文将结合最新的技术进展,深入解读为何我们需要告别传统的关键词高亮,转向更智能的“语义高亮(Semantic Highlight)”,以及这一技术变革如何成为消除搜索噪音的标准答案。更多关于AI前沿技术的深度分析,欢迎访问 AIGC.BAR。
传统高亮的局限:只看字面,不懂语义
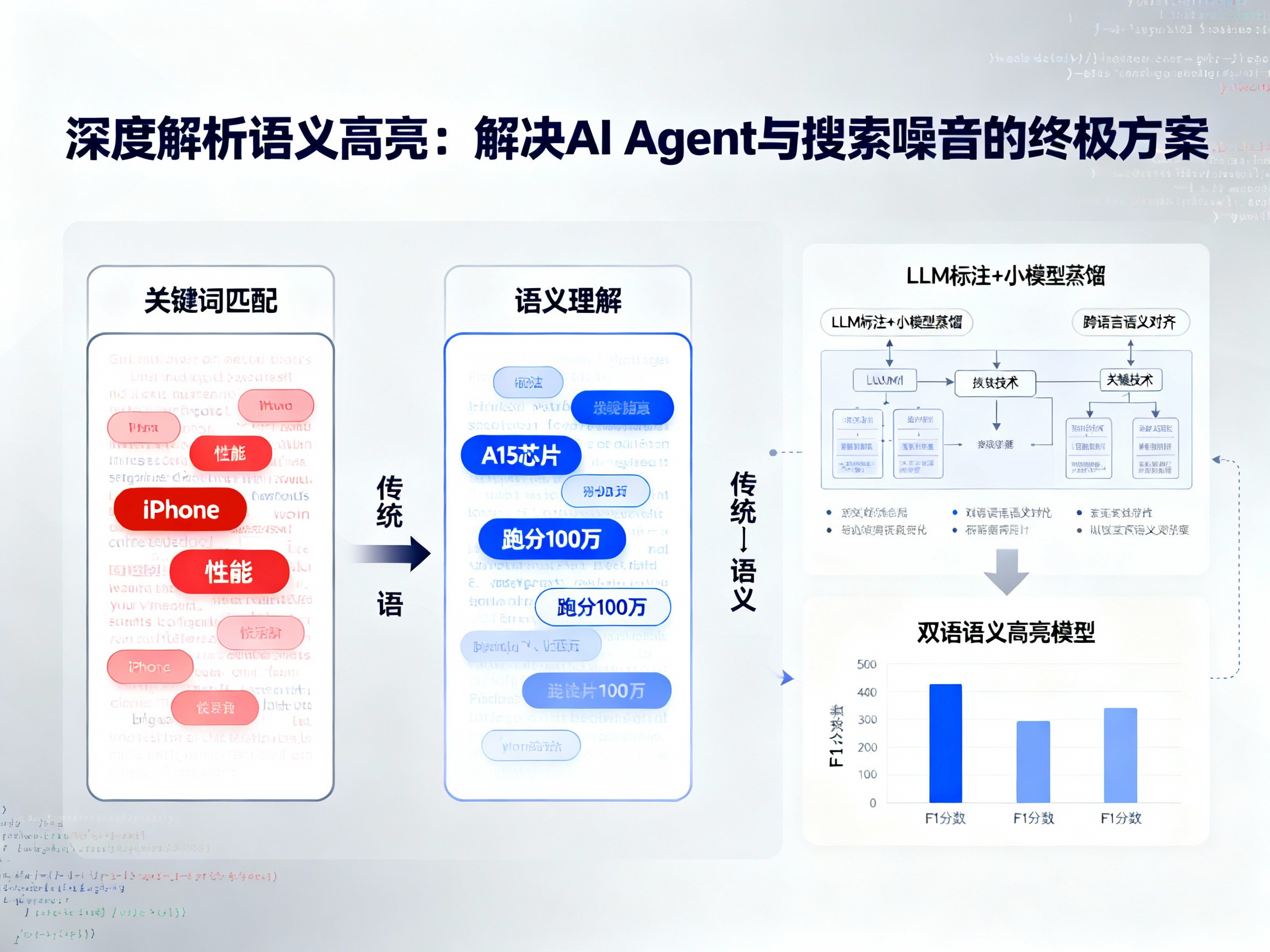
要理解语义高亮的革命性,首先得看清传统技术的短板。传统的搜索高亮逻辑非常简单粗暴:用户搜什么词,系统就在结果中把这些词标红或加粗。这种基于倒排索引的关键词匹配,在简单的电商搜索场景下或许勉强够用(比如搜“雨衣”高亮“雨衣”),但在AI驱动的复杂场景下,它彻底失效了。
1. 语义鸿沟无法跨越
在电商或内容社区,用户搜索“iPhone性能怎么样”,传统高亮只能机械地寻找“iPhone”和“性能”这两个词。如果一篇高质量的测评文章写的是:“搭载A15仿生芯片,跑分突破100万,日常使用流畅无卡顿”,这明明是完美的答案,但因为没有出现“性能”二字,传统系统会将其视为无关内容,完全不高亮。用户被迫阅读整段文字来人工过滤信息,效率极低。
2. RAG与Agent场景的灾难
在RAG系统中,用户的问题往往是自然的语言描述,例如“如何优化Python代码效率?”。传统高亮只能标出“Python”、“代码”等词。而真正的答案——“使用numpy向量化操作替代循环”——因为不包含查询词,会被完全忽略。
对于AI Agent而言,情况更糟。Agent往往会将用户的意图拆解为极其复杂的长指令,包含多个维度的限制条件。传统高亮面对这种长查询,只能零星地匹配到几个无关紧要的词(如年份、数据等),而错过了真正具备分析价值的结论性语句。简而言之,传统高亮只做到了“字面匹配”,却在“语义理解”上交了白卷。
现有语义高亮方案的痛点与挑战
语义高亮的核心愿景是:基于语义理解来标记关键内容。即使用户的查询词未出现在文本中,只要语义相关,系统也能将其高亮。这听起来很美好,但在落地过程中,市面上现有的方案普遍存在“偏科”现象。
1. 上下文窗口限制与泛化能力不足
OpenSearch曾推出的语义高亮模型基于BERT架构,其最大的硬伤在于上下文窗口太小(仅512 tokens)。在处理长篇技术文档或法律条文时,模型只能“看”到开头,后面的内容直接被截断。此外,这类模型往往在特定领域(in-domain)表现尚可,一旦跨领域(out-of-domain)应用,准确率就会断崖式下跌。
2. 多语言支持的匮乏
Naver发布的Provence系列虽然引入了上下文剪枝(Context Pruning)的先进理念,在英文环境下表现优异,但在多语言支持上却显得力不从心。其多语言版本XProvence虽然宣称支持中文,但由于训练数据的稀释,中文理解能力差强人意。更重要的是,许多优秀模型受限于CC BY-NC 4.0等协议,无法直接用于商业项目。
3. 任务目标的错位
许多模型原本是为“剪枝”任务设计的,策略是“宁滥勿缺”,倾向于保留更多文本以防遗漏。而语义高亮的要求是“精准定位”,需要更苛刻的筛选机制。直接套用剪枝模型,往往会导致高亮范围过大,失去了高亮的意义。
破局之道:双语语义高亮模型的崛起
面对上述市场空白,行业内开始探索专门针对中英文双语环境优化的轻量级模型。最新的技术突破采用了“LLM标注+小模型蒸馏”的思路,成功打造了既能理解深层语义,又能实时运行的高效模型。
1. 引入“思维链”的高质量数据构造
为了训练出更聪明的模型,开发者利用通义千问(Qwen)等大模型进行数据标注,并强制模型输出“思考过程”。这不仅提高了标注的准确性,还让训练数据包含了逻辑推理的痕迹。通过构建百万级(1M+)的中英文双语训练样本,新一代模型在数据源头上就占据了优势。
2. 跨语言的语义对齐
基于BGE-M3等强大的基座模型,新方案在训练时特别注重中英文的平衡。实测数据显示,这种专门优化的双语模型在F1分数上不仅击败了OpenSearch和Provence等老牌方案,更是在中文语境下大幅超越了XProvence。这意味着,无论用户是用中文提问还是英文检索,系统都能提供SOTA(State of the Art)级别的精准高亮。
实战案例:从“关键词”到“意图识别”
让我们通过一个具体的例子来感受语义高亮的威力。
问题: “谁写了《杀死一只神圣的鹿》?”
文本内容:
1. 《杀死一只神圣的鹿》是一部2017年的心理恐怖片,由约尔戈斯·兰西莫斯执导,剧本由兰西莫斯和埃夫西米斯·菲利波编写。
...
3. 故事基于古希腊剧作家欧里庇得斯的剧本《在奥利斯的伊菲革尼亚》。
在这个例子中,存在一个明显的陷阱:第3句提到了“剧本”和“欧里庇得斯”,如果是基于简单关键词或浅层语义的模型(如XProvence),很容易被误导,认为第3句是答案。
然而,真正优秀的语义高亮模型能够理解问题的语境是“电影”,因此它会准确地将高分打给第1句(明确指出了电影的编剧),而对第3句(原作剧本)给予较低的权重。这种能够区分“电影编剧”与“原作作者”细微差别的能力,正是语义高亮解决搜索噪音、提升Agent决策准确率的关键所在。
结语
从关键词匹配到语义理解,高亮技术的进化折射出的是AI从“感知”向“认知”的跨越。对于构建下一代RAG系统、AI资讯平台和智能Agent的开发者而言,拥抱语义高亮不再是一个可选项,而是提升用户体验、降低信息噪音的必经之路。
随着双语语义高亮模型的开源与服务化,我们有理由相信,未来的搜索体验将变得更加“懂你”——一眼即见答案,不再被无关信息裹挟。
想要了解更多关于大模型(LLM)、人工智能(AI)及AGI的最新动态和技术干货,请持续关注 AIGC.BAR,这里有最前沿的AI新闻和深度解读。
Loading...