.png?table=collection&id=cbe6506e-1263-8358-a4d7-07ce62fcbb3f&t=cbe6506e-1263-8358-a4d7-07ce62fcbb3f)
卡帕西首创AI议会模式:大模型匿名互评,揭秘谁是真正的AGI霸主
type
status
date
slug
summary
tags
category
icon
password
网址
在人工智能领域,安德烈·卡帕西(Andrej Karpathy)不仅是技术的先驱,更是创意编程的弄潮儿。最近,他再次成为了AI资讯的焦点,发布了一个名为“大模型议会”(LLM Council)的Web应用程序。这个项目不仅是一个有趣的编程实验,更可能为AGI时代的模型评估标准带来了全新的思考方向。
这一项目的核心理念非常超前:与其依赖人类费时费力地去评估每一个模型的优劣,不如让大模型们组成一个“议会”,通过匿名投票和辩论来决定谁的答案最完美。这不仅展示了LLM(大型语言模型)的协作潜力,也为我们提供了一个窥探AI内部逻辑的绝佳窗口。
“大模型议会”的运作机制:从独奏到合唱
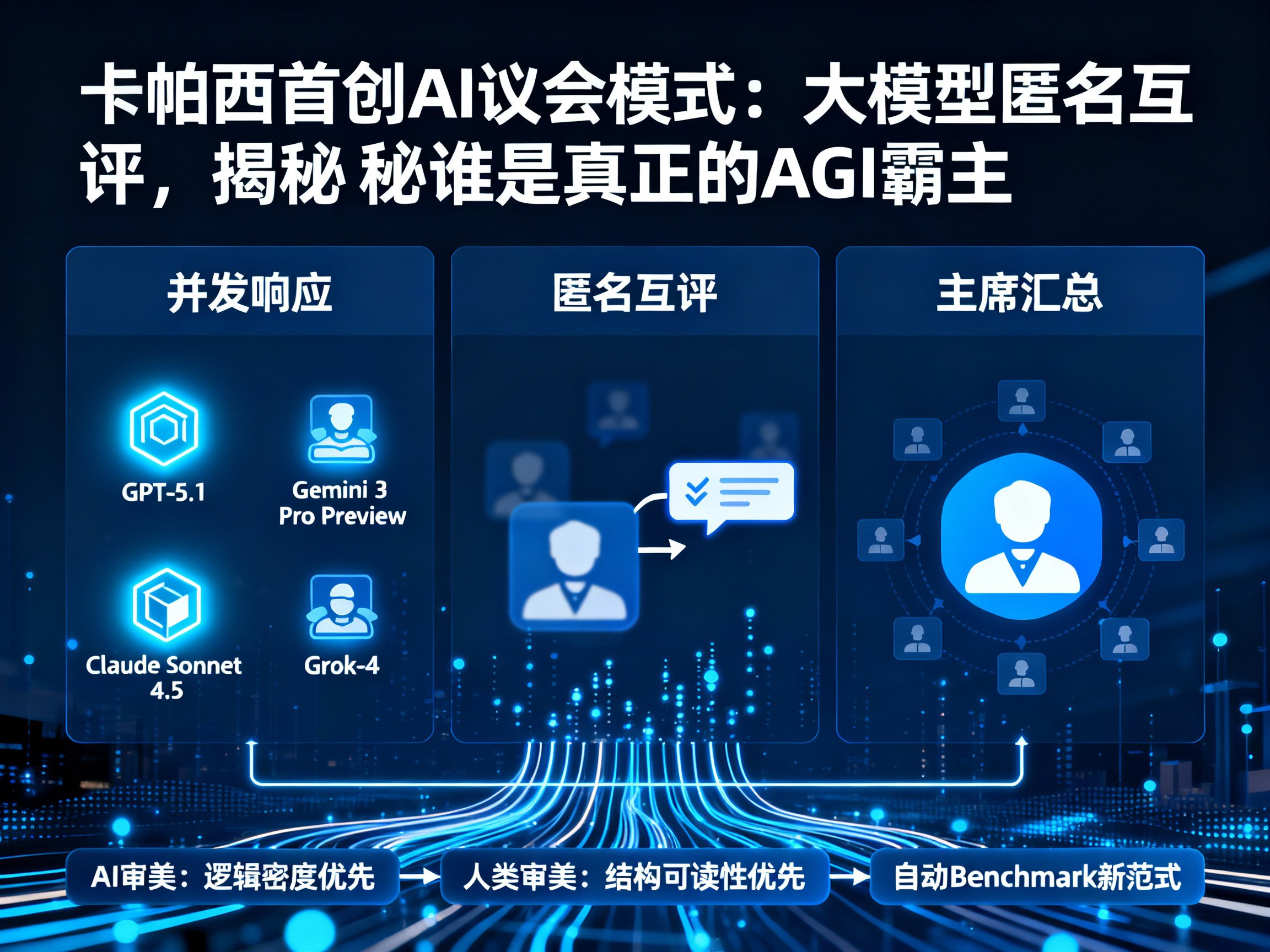
卡帕西构建的这个系统,表面上看起来与我们熟悉的ChatGPT聊天界面无异,但其后端逻辑却大有乾坤。它利用OpenRouter作为中间层,构建了一个复杂的“多模态会议室”。整个流程设计得非常严谨,主要分为三个关键步骤:
- 并发响应:当用户提出一个问题时,系统会同时调起多个顶尖大模型,包括传说中的GPT-5.1、Gemini 3 Pro Preview、Claude Sonnet 4.5以及Grok-4。这些模型会像参加考试一样,独立给出自己的答案。
- 匿名互评:这是最精彩的环节。系统会将所有模型的回答进行匿名化处理,然后分发给其他模型。每个模型都需要扮演“阅卷老师”的角色,根据准确性和洞察力对同行的答案进行打分和点评,并给出详细理由。
- 主席汇总:最后,系统会指定一个“主席模型”,它负责阅读所有的答案和评分意见,综合各方观点,最终生成一个集大成的回复呈现给用户。
这种机制极大地消除了单一模型的幻觉风险,通过“群体智慧”提升了最终输出的质量。
评分结果出乎意料:AI与人类的审美差异
在这个实验中,产生了一个非常有趣的现象,值得所有关注大模型发展的从业者深思。在“议会”的内部投票中,大模型们达成了一个惊人的共识:它们普遍认为GPT-5.1提供的答案是最强、最有洞见的,而Claude Sonnet 4.5则被评为相对较弱,Gemini 3和Grok-4位居中游。
然而,作为人类观察者的卡帕西却给出了完全不同的主观评价。在他看来,GPT-5.1虽然内容丰富,但结构显得松散;相反,Gemini 3的回答简洁凝练,信息处理得恰到好处,更符合人类的高效阅读习惯。至于Claude,虽然被AI同行“鄙视”,但在某些特定语境下可能更具亲和力。
这一差异揭示了一个关键问题:人工智能眼中的“好答案”与人类眼中的“好答案”可能存在本质区别。模型可能更偏向于逻辑密度和信息广度,而人类则更看重可读性和结构感。
自动Benchmark:AI评估的新范式
卡帕西的这个项目,实际上触及了AI新闻界讨论已久的一个痛点:如何公正地评估大模型?传统的Benchmark(基准测试)往往面临数据泄露和过拟合的问题。而“模型评价模型”的思路,或许能成为一种新的自动化Benchmark标准。
正如畅销书《Python机器学习》作者所言,这种思路非常有前景。更有趣的是,卡帕西发现,在匿名互评的过程中,模型们几乎没有表现出明显的偏见。它们表现得非常“谦虚”,经常愿意承认其他模型的匿名答案比自己的更好。这种“客观性”为未来建立基于LLM的自动化评估体系奠定了基础。
这也延续了卡帕西之前关于“深度阅读”的理念:将阅读和理解的过程外包给AI,让AI作为中介,先消化复杂内容,再根据读者的需求进行个性化转译。
结语与展望
“大模型议会”不仅仅是一个好玩的开源项目,它预示着未来AI产品形态的一种变革——从单一模型的对话,转向多模型协作的生态系统。随着提示词工程和模型推理能力的进化,未来的AI变现产品或许都会内置类似的“议会”机制,为用户提供经过多重验证的最佳答案。
在这个技术飞速迭代的时代,保持对最新工具和理念的敏感度至关重要。无论你是开发者还是普通用户,理解模型之间的协作与差异,都能帮你更好地驾驭这些强大的工具。
如果您想获取更多关于AI、AGI以及OpenAI、ChatGPT等前沿技术的深度解析和最新动态,欢迎访问 https://aigc.bar。在这里,您可以获取一手的AI资讯、AI日报以及实用的Prompt技巧,助您在人工智能浪潮中抢占先机。
Loading...