.png?table=collection&id=cbe6506e-1263-8358-a4d7-07ce62fcbb3f&t=cbe6506e-1263-8358-a4d7-07ce62fcbb3f)
GRPO训练告别过优化:快手与中大联手打造GRPO卫兵
type
status
date
slug
summary
tags
category
icon
password
网址
引言:当AI生成陷入“自嗨”困境
在人工智能(AI)飞速发展的今天,让大模型的产出更符合人类的偏好和指令,已成为AIGC领域的核心议题。其中,基于人类反馈的强化学习(RLHF)及其变体,如GRPO(Generalized RPO),在提升图像和视频生成模型(如FlowGRPO)的指令遵循能力方面取得了显著成效。然而,一个棘手的问题也随之浮现:过优化(Over-optimization)。
开发者们发现,在训练过程中,模型的代理奖励分数(proxy score)持续攀升,看似一片向好,但实际生成的图像质量和文本对齐度却在悄然下降。这种“自嗨式”的训练不仅浪费了宝贵的计算资源,更让优化后的模型在实际应用中表现不佳。为了解决这一AI资讯领域的前沿难题,快手可灵、中山大学及港中文MMLab等顶尖团队联手,推出了创新的解决方案——GRPO-Guard。
GRPO训练的“隐形杀手”:过优化陷阱
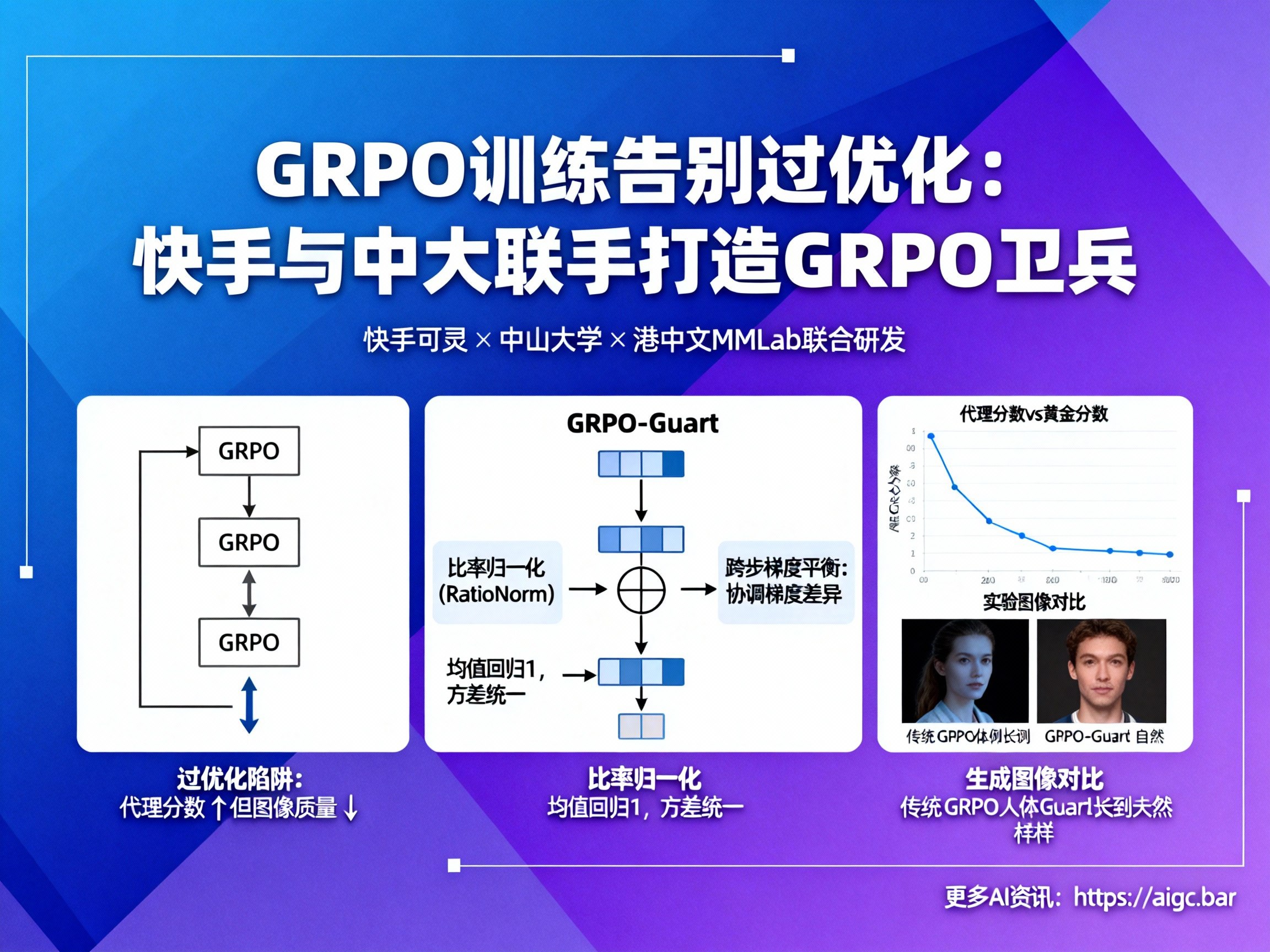
要理解GRPO-Guard的价值,我们必须先深入了解过优化问题是如何产生的。在GRPO的训练框架中,为了维持训练稳定,引入了一种名为“重要性比值裁剪(clip)”的机制。它的作用是约束那些过于“自信”的梯度更新,防止模型因为某一次剧烈的调整而偏离正确的优化轨道。
然而,研究团队通过实证分析发现,这个本应是“安全阀”的机制存在系统性偏差:
- 均值偏移:理想情况下,重要性比值的均值应接近1,以公平地限制正负两方面的极端梯度。但实际情况是,其均值长期低于1。这导致对“过度自信”的正向梯度约束不足,模型容易朝着错误的方向“狂奔”。
- 方差不一:在不同的去噪步骤中,该比值的分布方差差异巨大,使得在某些关键步骤中,clip机制近乎失效。
这两个缺陷共同导致了灾难性的后果:模型在追求更高代理奖励分数的过程中,牺牲了生成内容的多样性和真实性,陷入了“奖励黑客(reward hacking)”的陷阱,最终产出的图像质量不升反降。
GRPO-Guard登场:两大创新机制力挽狂澜
面对这一挑战,为每个步骤单独设定复杂的clip范围显然不切实际。GRPO-Guard巧妙地在原有框架上引入了两项关键改进,从根源上解决了问题。
1. 比率归一化(RatioNorm)
这是GRPO-Guard的核心武器。RatioNorm对每个去噪步骤的重要性比值分布进行标准化处理,强制使其均值回归到1附近,并统一其方差。这一操作简单而高效,直接修复了失效的clip机制。
- 修复前 (FlowGRPO):均值小于1,破坏性的正样本梯度无法得到有效约束,导致模型过度优化。
- 修复后 (GRPO-Guard):均值接近1,正负样本梯度得到均衡约束,训练过程更加稳健,有效避免了质量退化。
通过这种方式,GRPO-Guard为训练过程重新装上了可靠的“护栏”。
2. 跨步梯度平衡
除了RatioNorm,GRPO-Guard还引入了跨步梯度平衡机制。它旨在协调不同去噪步骤之间的梯度差异,确保整体优化过程更加平滑和一致,进一步增强了训练的稳定性。
实验为证:GRPO-Guard的显著成效
理论上的创新最终需要通过实验来验证。研究团队在FlowGRPO、DanceGRPO等多种GRPO算法,以及SD3.5-M、Flux1.dev等不同扩散骨干模型上进行了全面测试。
结果令人振奋:
- 缓解质量下降:在传统的GRPO训练中,随着代理分数的提升,代表真实人类评估的“黄金分数”(gold score)往往会出现明显下降。而引入GRPO-Guard后,这一退化趋势被显著遏制,模型在整个训练后期都能保持较高的图像质量。
- 提升多样性:在一些任务(如PickScore)中,基线模型训练后期生成的图像会出现人体比例失调、人脸趋同等问题,严重影响了生成的多样性。GRPO-Guard则有效缓解了这些现象,生成的内容更加丰富和自然。
- 广泛适用性:无论是在文本渲染、通用评估(GenEval)还是偏好评分(PickScore)等多种任务中,GRPO-Guard都展现出稳定且显著的性能提升,证明了其强大的通用性。
总结与展望:迈向更稳健的AIGC未来
GRPO-Guard作为首个系统性解决GRPO视觉生成过优化问题的研究,其提出的比率归一化等方法,为人工智能模型的稳定训练提供了全新的思路。它从优化过程本身入手,有效地缓解了代理奖励与真实质量之间的鸿沟。
当然,过优化问题的根源在于代理分数(proxy score)与真实评估(gold score)之间的差距。GRPO-Guard虽是“良药”,但要“根治”,未来仍需构建更精准、更接近人类真实偏好的奖励模型。
这项研究不仅是AI新闻中的一次技术突破,更为整个AIGC领域的发展指明了方向:我们需要的不仅是会“刷分”的模型,更是能稳定创造高质量、高多样性内容的可靠伙伴。想要获取更多前沿的AI资讯和深度解读,欢迎访问AIGC导航站 https://aigc.bar,与我们一同见证人工智能的未来。
Loading...