.png?table=collection&id=cbe6506e-1263-8358-a4d7-07ce62fcbb3f&t=cbe6506e-1263-8358-a4d7-07ce62fcbb3f)
AI文科推理有多离谱?林黛玉的外国平替难寻
type
status
date
slug
summary
tags
category
icon
password
网址
AI的“林黛玉式”推理困境:类比能力的深层挑战
想象一下,如果你让一个先进的大语言模型(LLM)为中国古典文学中的经典人物林黛玉寻找一个外国文学中的“平替”,它能给出一个既深刻又令人信服的答案吗?这个看似脑洞大开的问题,实则触及了当下人工智能,尤其是大型模型最核心的软肋之一——类比推理能力。人类大脑可以轻松地举一反三,在浩瀚的文学作品中寻找到意境相近、性格相似的角色。然而,研究表明,AI在这一领域,尤其是面对复杂、抽象的文科类比时,表现可能远超我们想象的“离谱”。
类比:思维的基石与AI的“阿喀琉斯之踵”
认知科学家侯世达(Douglas Hofstadter)在其著作《表象与本质》中指出,类比不仅仅是语言或逻辑的工具,更是思维的基本单位。从爱因斯坦构思广义相对论时将引力场类比为蹦床上的重物,到我们用“意识像冰山”来理解其复杂性,类比渗透在我们日常的语言、创造和理解过程中。它激活创造力,解释未知,是人类智能的关键组成部分。
然而,对于AI而言,类比推理却是一个巨大的挑战。虽然大模型在海量数据上展现出惊人的模式识别和生成能力,但它们是否真正“理解”了类比背后的深层逻辑和抽象关系,而非仅仅是数据中的表面关联?
“马甲”下的真相:AI类比能力的鲁棒性测试
为了探究大模型是否具备真正的类比推理能力,研究人员设计了一系列严谨的测试。早期的研究(如Webb等人,2023)试图通过“零尝试推理”(即不提供示例,让模型自行推理)来评估GPT-3的类比能力,在字符串、数字矩阵和故事类比任务上,GPT-3的表现似乎令人鼓舞,甚至优于平均人类水平。
但更深入的质疑随之而来:模型是否仅仅是在“回忆”训练数据中的模式,而非进行抽象思考?当问题的形式或表达发生变化时,它们的表现是否依然稳定?
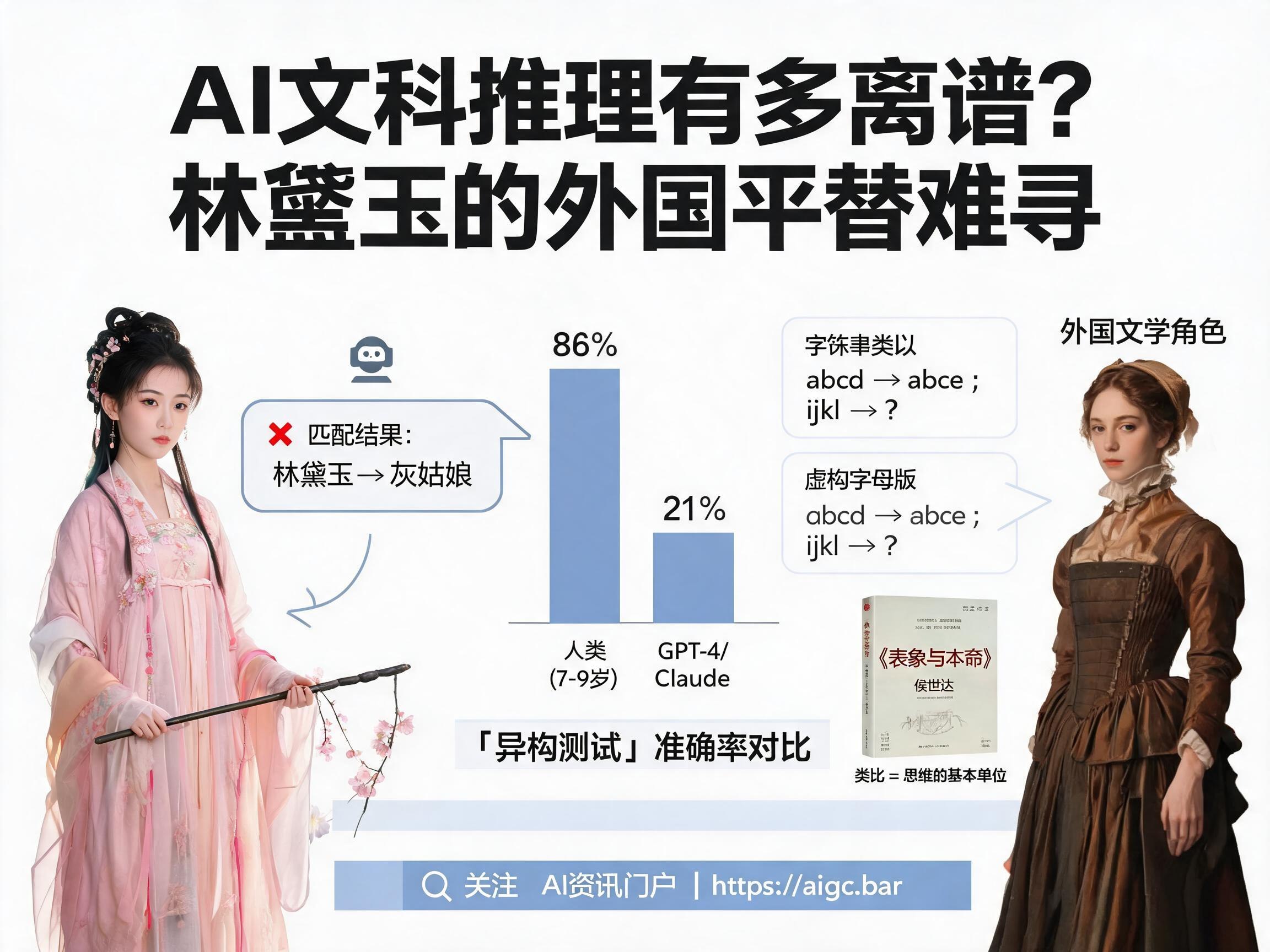
圣塔菲研究院的Lewis & Mitchell(2024)进一步设计了更具挑战性的变体测试。他们为原本的类比任务披上“马甲”,例如:
* 字符串类比:最经典的如
abcd → abce; ijkl → ?,模型需要识别出“最后一个字母+1”的规则。
* 数字矩阵:考察对数字模式的识别与推演。
* 故事类比:判断不同故事间的相似性,涉及常识和情境理解。这些研究的关键在于,他们引入了“异构”元素,即不改变问题的本质逻辑,但改变其表现形式。例如,使用虚构字母表(随机打乱字母顺序)或符号字母表(用符号替代字母),或者改变数字矩阵中空白位置,甚至重写故事的表述方式。
惊人结果:AI表现“断崖式下跌”,不如7岁儿童
研究结果令人警醒。当测试引入这些“马甲”后,无论是GPT-3、GPT-3.5还是更先进的GPT-4,其准确率都出现了断崖式下跌。在某些情况下,它们的表现甚至不如7-9岁的儿童。
Stevenson CE等人(2024)的实验特别指出,在面对拉丁字母表时,GPT-4o和Claude-3.5的平均准确性尚可;但当题目换成希腊字母,准确性便显著下降;而到了符号列表,其准确性甚至不如孩童。而其他开源模型如Llama-3.1和Gemma-2的表现下降更为明显。
这说明,当问题脱离了训练数据中常见的“表面特征”时,大模型就难以捕捉到隐藏在“马甲”下的本质规则。人类(包括儿童)则能展现出更强的鲁棒性和抽象理解能力,即使面对新颖的表示方式,也能通过类比推理找到答案。
文科推理的“离谱”之处:不只是数字游戏
故事类比任务,本应是大模型的“主场”,因为它们在自然语言处理方面拥有海量数据和强大能力。然而,即便在此,研究也揭示了其局限性。
- 答案顺序偏好:GPT-4等模型倾向于选择列表中的第一个答案,而人类则不受此影响。
- 表述方式敏感性:用不同的语言重述故事,会显著降低模型在故事类比问题上的准确性。
这表明,即使在看似“文科”的领域,大模型也可能过度依赖特定的答案格式和表述,而非真正理解故事背后的因果关系、人物动机或情感逻辑,无法像人类那样进行灵活的常识性类比。
提升AI类比能力:挑战与未来方向
这一系列研究为我们敲响了警钟:声称大语言模型已具备通用推理能力可能为时过早。在教育、法律、医疗等需要高度信任和精确推理的领域,AI的这种“脆弱性”不容忽视。
那么,如何才能提升AI的类比能力?
- 开发稳健性测试:需要设计标准化的测试集,模拟真实世界中可能出现的细微变化和新情况,以衡量AI系统的适应性和可靠性。
- 类比推理框架:研究表明,通过类比推理框架,让大模型自动生成新规则来应对未知场景,能够显著提升其性能和泛化能力。
- 借鉴结构化思维模式:未来研究可以从中国传统文化中汲取灵感,例如对联与律诗,它们本质上是精妙的类比系统,蕴含严谨的对应规则和丰富的语义关联。通过结构化的数据集(如中文互联网社区的“弱智吧”标题,或更具学术性的结构化数据)对模型进行微调,可能为增强其类比推理能力开辟新途径。
- 跨文体、跨文化类比:探索模型在处理风格差异巨大的作品(如金庸武侠与《哈利波特》)或不同文化背景下的类比准确性,以及模型是否表现出特定的人群偏好。
结论:AI的“读懂”之路,任重道远
“让AI给林黛玉找个外国平替”这个看似简单的文学类比问题,实则揭示了当前大模型在抽象理解、跨领域迁移和鲁棒性方面的巨大差距。它们擅长模式匹配,却难以触及人类思维中类比的精髓。
尽管AI技术飞速发展,但要让它们真正“读懂”人类复杂的隐喻与类比,实现与人类同等水平的推理能力,我们还有很长的路要走。这不仅是技术上的挑战,更是对人工智能未来发展方向的深刻反思。
想要了解更多关于AI最新进展和使用技巧,敬请关注AI资讯门户。
Loading...