.png?table=collection&id=cbe6506e-1263-8358-a4d7-07ce62fcbb3f&t=cbe6506e-1263-8358-a4d7-07ce62fcbb3f)
挑战激光雷达!LingBot-Map如何用单摄实现丝滑3D实时建图
type
status
date
slug
summary
tags
category
icon
password
网址
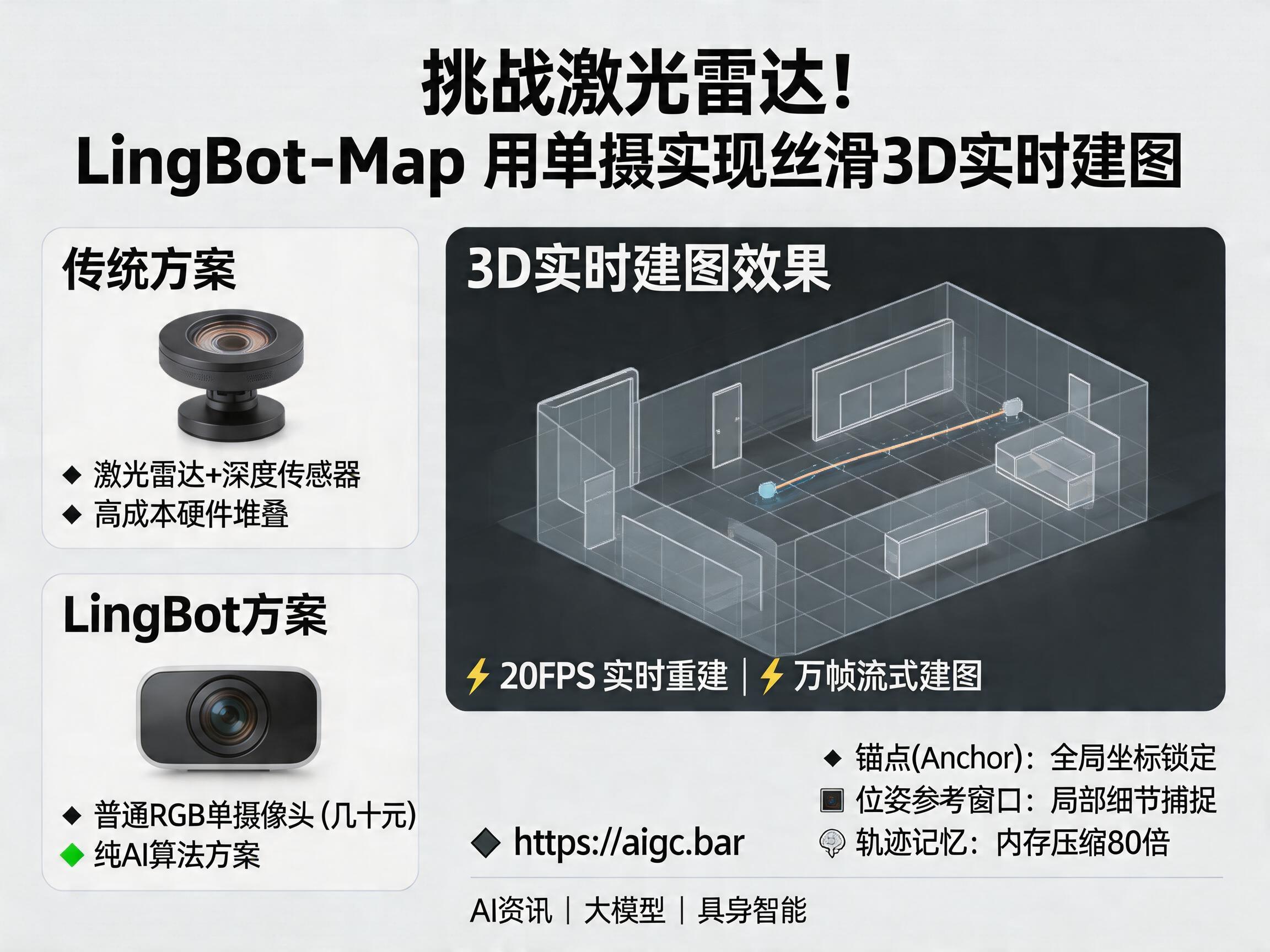
在具身智能领域,机器人如何“看懂”世界一直是个难题。长期以来,激光雷达(LiDAR)被视为机器人导航与建图的“黄金标准”,但其高昂的成本却成为商业化落地的巨大阻碍。近日,中国团队开源的LingBot-Map模型彻底打破了这一格局,仅凭一颗几十块钱的普通RGB摄像头,便实现了万帧流式3D重建,在全网引发了广泛关注。
视觉SLAM的新范式:告别昂贵的激光雷达
LingBot-Map的出现,让行业看到了“低成本、高性能”的无限可能。在传统的机器人感知方案中,为了获得高精度的环境地图,往往需要堆叠激光雷达、深度传感器等硬件,导致整机成本居高不下。LingBot-Map通过纯视觉方案,在不需要深度传感器的情况下,依然能够以20FPS的速度实时构建高质量3D地图。
这种技术的突破,对于家用服务机器人、低速配送车等对成本极其敏感的品类而言,无疑是一次降维打击。它证明了通过先进的深度学习算法,完全可以弥补硬件上的缺失,实现甚至超越传统工业级方案的感知效果。更多前沿的AI资讯与大模型应用,欢迎访问 https://aigc.bar 获取最新动态。
核心技术揭秘:GCA机制与选择性记忆
流式3D重建最大的难点在于“边看边建”:如何在保持实时性的同时,既不遗忘历史信息,又不因内存爆炸而崩溃?LingBot-Map引入了创新的几何上下文注意力(GCA)机制,巧妙地解决了这一难题。
GCA机制通过维护三种不同粒度的空间记忆,实现了对内存的高效管理:
* 锚点(Anchor):锁死坐标系,保证长距离轨迹的精度,确保模型即便跑了一万帧,依然记得起点位置。
* 位姿参考窗口(Pose-reference window):专注于当前位置附近的细节,捕捉密集几何信息。
* 轨迹记忆(Trajectory memory):通过压缩历史帧的摘要Token,将内存增长速率降低了约80倍,使得超长视频的实时建图成为可能。
这种“选择性记忆”的设计,让机器人能够像人一样,既能关注眼前的细节,又能通过关键路标维持全局定位的连贯性。
具身智能的技术闭环:从感知到行动
LingBot-Map的开源不仅是一个独立的模型发布,更是蚂蚁灵波在具身智能领域构建完整技术栈的关键一环。目前,该团队已经形成了一套从感知到决策的完整闭环:
1. LingBot-Depth:负责深度感知,解决透明、反光材质的深度估计难题。
2. LingBot-Map:负责实时空间理解,构建三维场景地图。
3. LingBot-World:负责物理模拟,与环境进行实时交互。
4. LingBot-VLA/VA:负责决策与行动,执行复杂任务。
这种全栈开源的策略,为全球机器人开发者提供了极具参考价值的工具。无论是从事AGI研究,还是关注LLM在物理世界落地的开发者,都能从中汲取灵感。
结论与展望
LingBot-Map的成功,是AI算法赋能硬件的一次典型示范。随着人工智能技术的不断演进,机器人将不再仅仅是冷冰冰的机器,而是能够真正理解并适应复杂环境的智能伙伴。未来,随着该技术的进一步优化,我们有望看到更多低成本、高智能的机器人产品走进千家万户。
如果你对AI领域的前沿进展、AI变现机会或提示词工程感兴趣,请持续关注 https://aigc.bar,我们将为您提供最及时的AI日报与深度分析。在这个大模型时代,掌握核心技术与趋势,正是通往未来的关键钥匙。
Loading...