.png?table=collection&id=1e16e373-c263-81c6-a9df-000bd9c77bef&t=1e16e373-c263-81c6-a9df-000bd9c77bef)
不平衡数据下对比学习新突破:从训练动态到剪枝优化全解析 | AI新闻
type
status
date
slug
summary
tags
category
icon
password
网址
引言
在当今的人工智能领域,对比学习(Contrastive Learning)已成为表征学习的基石。它通过在表征空间中拉近正样本对、拉远负样本对,使得模型能够在无需大量标注的情况下捕捉到深层特征。然而,现实世界中的数据往往呈现极端的“长尾分布”,即少数类别样本稀缺。这种不平衡性严重制约了对比学习的性能。
近期,来自新泽西理工学院的廖海旭博士及其团队发表了题为《Theoretical Analysis of Contrastive Learning under Imbalanced Data: From Training Dynamics to a Pruning Solution》的论文。该研究深入探讨了不平衡数据如何干扰大模型的特征学习,并提出了一种创新的剪枝解决方案。本文将为您深度解读这一前沿AI资讯,探索其背后的理论逻辑与实践价值。
揭秘对比学习的三阶段训练动态
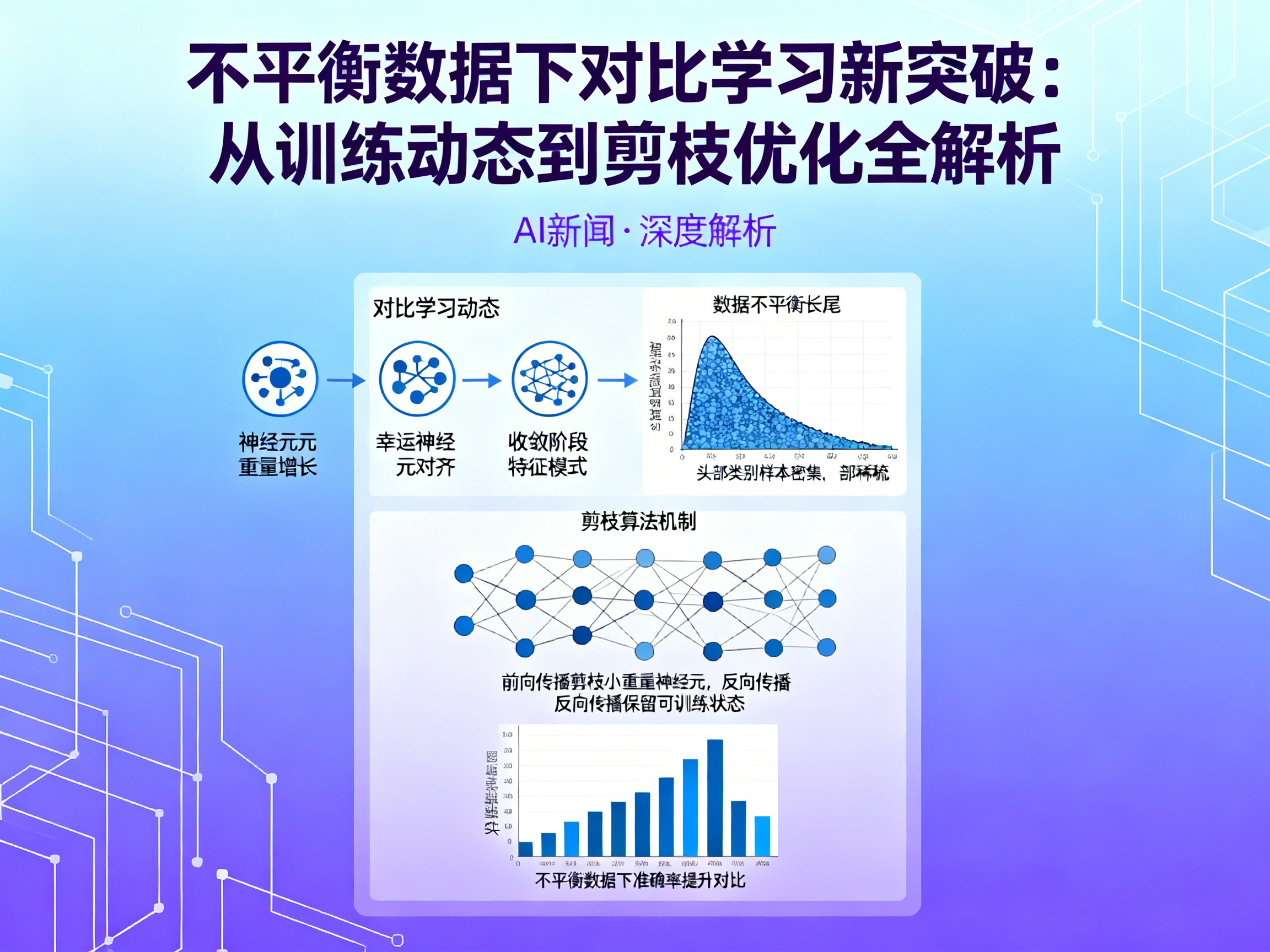
研究团队首先构建了一个基于 Transformer 编码器的理论框架,将对比学习的训练过程细致地划分为三个动态阶段。这对于理解LLM及视觉模型如何从原始数据中提取信息至关重要。
在第一阶段,神经元权重开始沿特征方向增长,增长速率直接受特征出现的频率影响,同时噪声分量受到抑制。进入第二阶段后,所谓的“幸运神经元”开始脱颖而出,与主导特征方向强力对齐,而普通神经元则在这些幸运神经元的界定下保持受控,确保特征的纯净度。
最终,在收敛阶段,每个神经元都会形成特定的特征对齐模式。理想情况下,一个神经元应专门学习单一特征,但在不平衡数据下,这种“专门化”过程会遭遇严重阻碍。
数据不平衡对表征学习的三重打击
研究指出,特征频率的比率是决定神经元专门化程度的关键。当数据分布不均时,对比学习会面临以下三个相互关联的负面影响,这也是目前人工智能研究中急需解决的痛点:
- 少数特征学习强度弱:由于样本量少,少数类特征在权重空间中的增长幅度远小于多数类,导致其特征捕获不完整。
- 特征混合现象严重:神经元倾向于学习多个特征的混合体,而非保持与单个特征的精准对齐,这降低了表征的判别性。
- 专门化神经元数量锐减:能够专门处理单一特征的神经元总数随着不平衡程度的增加而减少,迫使模型需要更大的规模才能勉强覆盖所有特征。
这些发现揭示了为什么传统对比学习在处理长尾数据时往往表现不佳,为后续的Prompt优化和模型调优提供了理论支撑。
剪枝算法:逆转不平衡的“手术刀”
为了解决上述问题,研究团队提出了一种基于幅值的动态剪枝方案。这种方法在AI新闻界引起了广泛关注,因为它不仅提升了性能,还展示了剪枝技术在模型压缩之外的全新用途。
该算法的核心逻辑是在前向传播过程中,动态移除幅值较小的神经元权重,但在反向传播时保留所有参数的可训练状态。由于学习少数特征的神经元初始幅值较小,它们更容易被剪枝机制“选中”。
这种看似“舍弃”的行为,实际上在梯度更新中放大了包含少数特征样本的贡献。通过这种机制,剪枝强化了少数特征的梯度更新,推动更多神经元专门化地学习这些稀有特征,从而在收敛时实现与多数特征同阶的表征规模。
实验验证与未来展望
实验结果令人振奋:该剪枝方案在多个数据集上均持续提升了准确率。特别是在不平衡程度极高的情况下,性能提升尤为显著。更重要的是,它有效缩小了头部类别与尾部类别之间的性能差距,实现了更均衡的表征学习。
这一研究不仅为对比学习提供了坚实的理论基础,也为AI变现和工业级应用中的数据偏差问题提供了实用的解决方案。随着AGI进程的加速,如何让模型在有限且不平衡的数据中学习到更稳健的知识,将是未来研究的核心方向。
如果您想了解更多关于chatGPT、openai以及全球最新AI日报内容,欢迎访问 AI门户,获取最前沿的技术深度解析与行业动态。
结论
廖海旭博士团队的研究为我们展示了深度学习理论的魅力:通过对训练动态的微观观察,能够推导出解决宏观性能瓶颈的优雅方案。剪枝不再仅仅是减负的工具,更成为了平衡知识学习的利器。在追求更大、更强的大模型道路上,这种对底层机制的深刻洞察将指引我们走向更高效的人工智能未来。
Loading...