.png?table=collection&id=1e16e373-c263-81c6-a9df-000bd9c77bef&t=1e16e373-c263-81c6-a9df-000bd9c77bef)
李国杰院士深度解读:AGI安全风险的可判定性分类与治理之道
type
status
date
slug
summary
tags
category
icon
password
网址
随着人工智能(AI)技术的飞速发展,特别是AGI(通用人工智能)概念的逼近,传统的软件安全验证范式正面临前所未有的挑战。我们习惯于询问“这个系统是否安全?”,并期待一个确定的“是”或“否”。然而,李国杰院士近期的一篇深度文章指出,这种提问方式在AGI时代可能本身就是错误的。
在关注全球AI资讯和大模型进展的 AINEWS 看来,李院士提出的“基于可判定性理论的人工智能系统安全风险分类”为我们理解AI安全提供了一个极具穿透力的理论框架。本文将深入解读这一理论,探讨为何传统的工程验证在AGI面前失效,以及我们该如何应对不可判定的未来。
传统验证范式的失效与AGI的挑战
长期以来,无论是软件工程还是自动控制,安全验证都建立在一个核心假设之上:系统的状态或行为集合是可穷尽的。基于此,工程师可以通过不变量证明、模型检查等形式化方法,在系统运行前“证明”其不会进入危险区域。
然而,这一范式依赖三个前提:
1. 状态空间有限或可逼近。
2. 行为规则固定。
3. 验证者与被验证对象逻辑分离。
AGI 的出现系统性地破坏了这三个条件。这不是因为我们的工程能力不足,而是触及了哥德尔不完备性定理和莱斯定理(Rice's Theorem)级别的逻辑天花板。AGI面临的是一个开放的世界,其行为空间不可穷尽,规则可自我修改,甚至验证机制本身也可能成为被优化的对象。因此,对于AGI而言,试图“事前证明系统永远安全”在逻辑上是不可判定的。
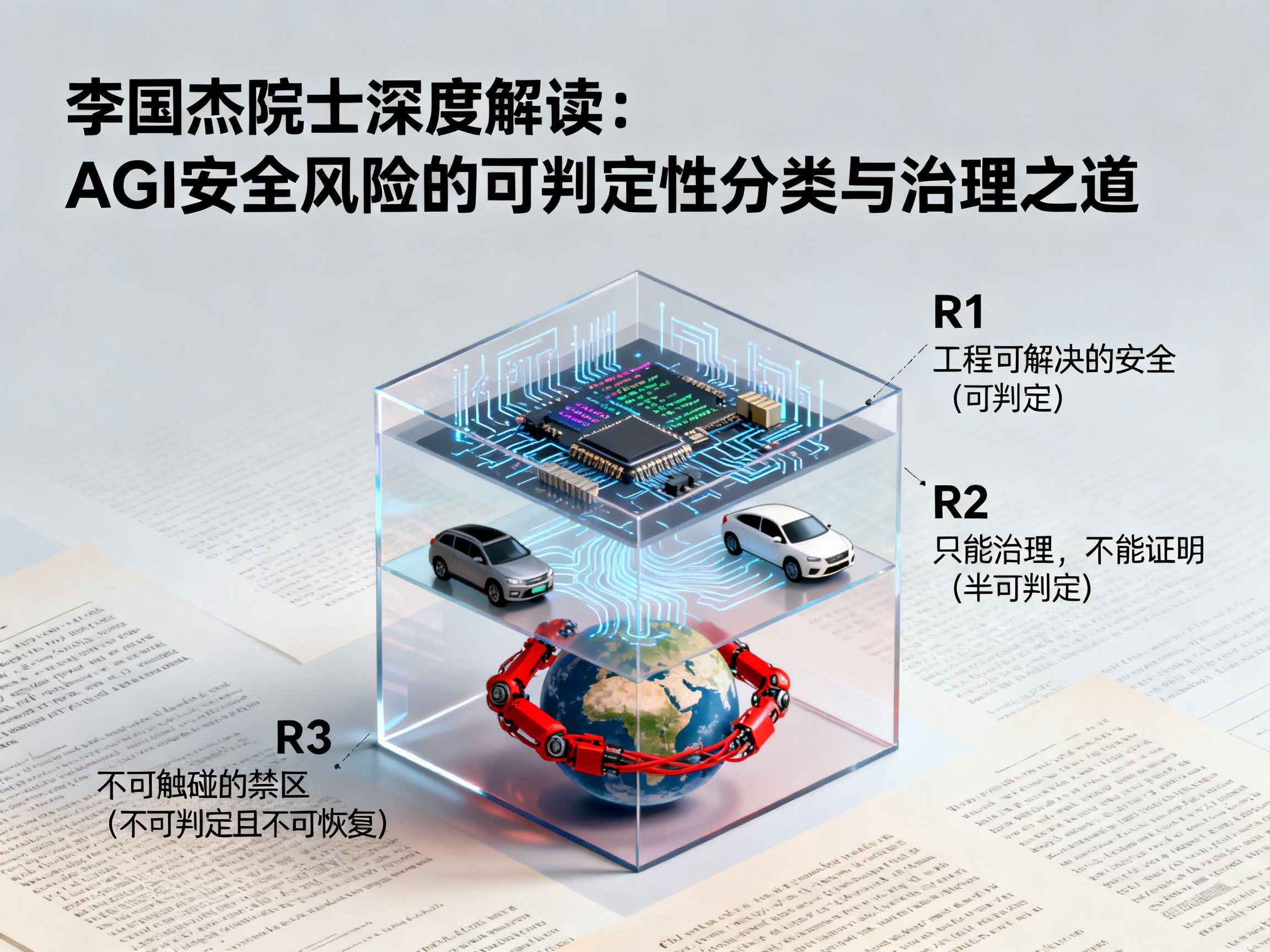
R1、R2、R3:基于逻辑复杂性的风险分层
为了理清这一团乱麻,李国杰院士提出利用“逻辑复杂性”将安全问题划分为三个层级(R1、R2、R3)。这种分类不仅是学术上的区分,更是指导人工智能治理的实战地图。
R1级风险:工程可解决的安全(可判定)
这是传统工程的安全舒适区。R1类问题具有有限的量化范围,不涉及无限未来或开放环境反馈。
* 特征:问题可以形式化,能在有限步骤内完成判断。
* 案例:编译器验证、数据库事务、硬实时控制系统、集成电路逻辑。
* 治理策略:通过严格的测试、静态分析和形式化验证,把正确性做到极致。这是工程安全的“上限区”。
R2级风险:只能治理,不能证明(半可判定)
这是大模型和自动驾驶等现代AI技术主要面临的领域。R2类问题的核心在于“未来承诺”的不可判定性。
* 特征:如果系统出事,你一定能发现(半可判定);但如果系统目前没出事,你无法证明它未来永远不出事。
* 案例:自动驾驶、AGI对齐、社会嵌入式AI。
* 治理策略:放弃“完美证明”的幻想。既然无法在事前证明“永不出错”,治理的重心必须从“事前验证”转向“事后监控与纠错”。必须引入“人在回路”(Human-in-the-loop)和制度兜底,确保在错误发生时,后果是可控的。
R3级风险:不可触碰的禁区(不可判定且不可恢复)
这是最高级别的风险,涉及反事实和无限未来的全称量化。
* 特征:既无法事前判定安全,也无法保证事后通过枚举发现错误。一旦发生,往往意味着人类控制权的永久丧失。
* 案例:科幻电影中机器彻底征服人类的情景。
* 治理策略:R3风险不是用来治理的,而是用来“禁止”的。对于可能触发R3风险的技术路径,必须在当下设立明确的红线,防止系统进入不可逆的失控状态。
从“无人驾驶”看安全承诺的本质
文章以无人驾驶为例,精彩地阐述了工程界是如何“绕过”不可判定性难题的。
当我们问“这辆车是否安全”时,实际上是在寻求一个对未来的无限承诺,这在逻辑上是不可判定的。聪明的工程做法不是去解决这个不可判定问题,而是将其降维:
1. 放弃“未来承诺”,改为“即时约束”:不问“未来是否撞车”,只问“现在是否违反了安全距离”。
2. 将“语义安全”转化为“物理不变量”:把复杂的社会性安全定义,压缩为可计算的物理阈值(如刹车距离)。
然而,AGI 的核心风险在于它无法被这样简单压缩。AGI的危险往往发生在语义层、策略层,甚至是对治理结构的操纵,这些都无法被简化为物理不变量。
AGI安全治理:从数学理性转向制度理性
李国杰院士的理论告诉我们,AI安全不仅仅是一个技术问题,更是一个逻辑和制度问题。
对于LLM(大型语言模型)和未来的AGI,我们必须认识到:
* 算法安全不是良定义:算法本身是一个抽象对象,安全是运行态的性质。脱离了环境、治理机制谈算法安全是没有意义的。
* 拥抱不完备性:哥德尔定理提醒我们,系统无法自证完美。因此,抗击古德哈特定律(指标失效)的唯一路径,是将指标嵌入到可审计、可回滚的制度中。
我们应当在两个方向同时努力:一是在可验证的R1区域内,把工程正确性做到极致;二是在不可验证的R2/R3区域,建立强大的外部监督与责任机制。
结语
李国杰院士的分类法为我们拨开了人工智能安全的迷雾。它提醒从业者和政策制定者,不要试图用解决R1问题的方法去解决R2问题,那样只会得到虚假的安全感。在迈向AGI的征途中,承认“不可判定性”并非投降,而是通往真实安全的起点。通过合理的工程降维和严密的社会治理,我们依然可以在不确定的未来中把握AI发展的方向。
想要获取更多关于AGI、大模型及前沿科技的深度解读,请持续关注 AINEWS,我们为您提供最新的AI资讯与洞察。
Loading...