.png?table=collection&id=1e16e373-c263-81c6-a9df-000bd9c77bef&t=1e16e373-c263-81c6-a9df-000bd9c77bef)
破解Agent训练难题:港中文与美团推出Reagent过程分框架
type
status
date
slug
summary
tags
category
icon
password
网址
破解奖励稀疏:为什么Agent训练不能只看结果
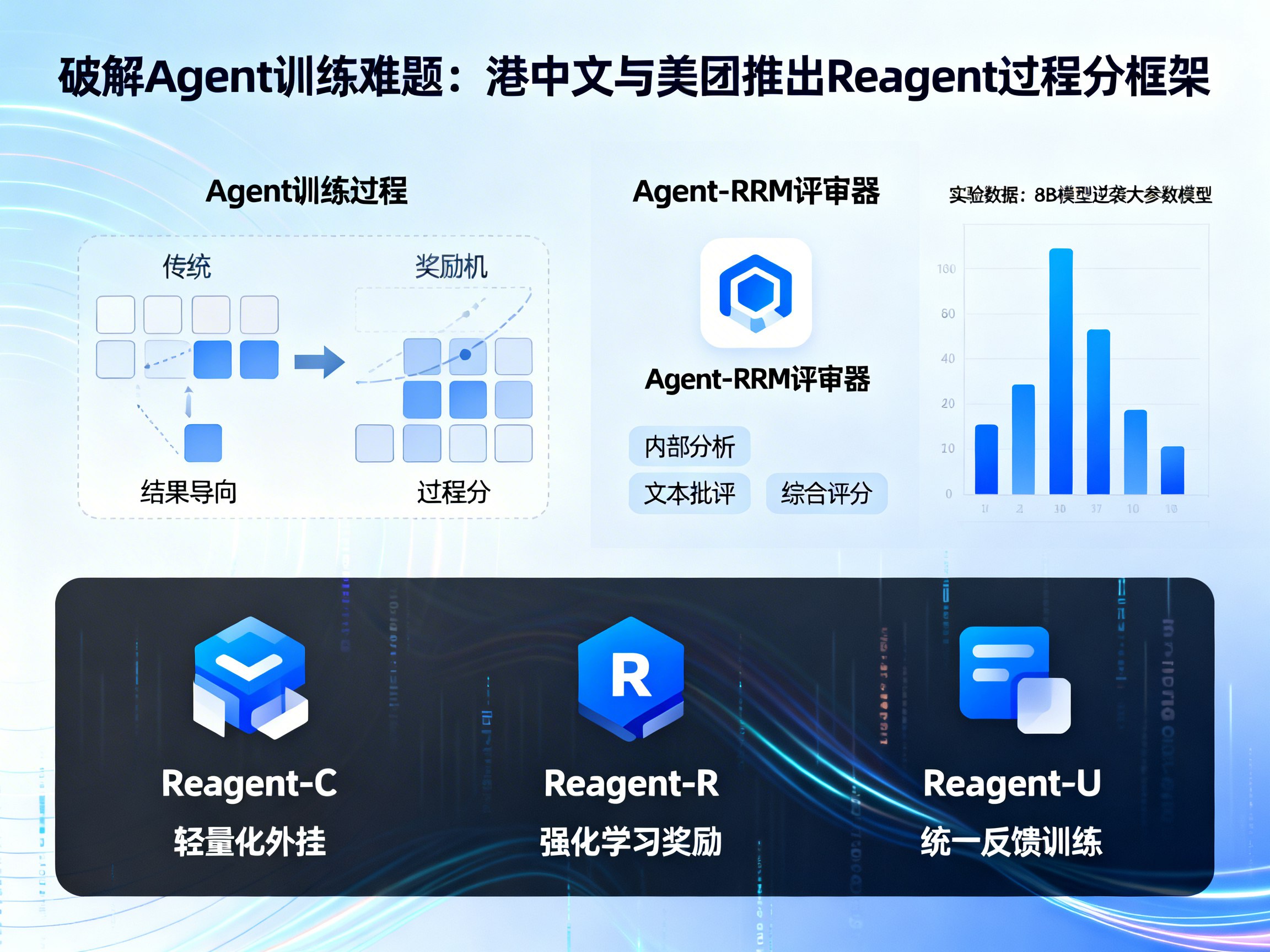
在当前大语言模型(LLM)与智能体(Agent)的快速演进中,如何有效训练Agent执行复杂任务一直是业界难题。传统的训练模式往往采用“结果导向”的奖励机制:即Agent完成了一系列操作后,只有最终答案正确才给予奖励,否则记为零分。
然而,对于需要多轮对话、调用外部工具、浏览网页或编写代码的长链任务而言,这种“只看终局”的做法存在巨大的局限性。一个在中间步骤仅差毫厘的失败过程,与一个从第一步就彻底跑偏的过程,在传统的稀疏奖励面前没有任何区别。这导致模型无法从“有价值的失败”中学习。为了解决这一矛盾,香港中文大学联合美团视觉智能中心提出了全新的 Reagent 框架,旨在为Agent的每一步思考打出“过程分”。
想要了解更多前沿 AI资讯 和 AI新闻,欢迎访问 AI门户,获取最新的 LLM 与 AGI 技术动态。
Agent-RRM:像老师改卷一样评估思考过程
Reagent框架的核心在于引入了一个专门的评审器——Agent-RRM(Reasoning Reward Model)。研究团队意识到,Agent不仅需要知道“做没做对”,更需要知道“想得对不对”以及“工具用得好不好”。
为了训练这个评审器,团队构建了一套包含真实Agent执行轨迹的数据集。这些轨迹涵盖了各种情况:有的逻辑严密但执行偶发失误,有的则是通过乱猜碰巧答对。Agent-RRM会对每一条轨迹生成详细的“阅卷意见”,包括:
1. 内部分析:深度剖析Agent的推理逻辑。
2. 文本批评:指出具体的工具调用错误或思维偏差。
3. 综合评分:给出0-1之间的细粒度分值。
这种机制确保了那些思路清晰、工具使用合理的轨迹即使最终失败也能获得相对较高的分数,从而引导模型向正确的逻辑路径靠拢,这对于提升 Prompt 编写和 提示词 优化具有重要的参考价值。
Reagent框架的三种实战部署模式
为了将Agent-RRM的反馈有效转化为模型的进化动力,Reagent框架设计了三种由浅入深的策略:
1. Reagent-C(基于批评的推理)
这是一种轻量化的外挂模式。它不修改Agent的原有参数,而是在推理阶段增加一个“反思”环节。Agent先给出一个初步方案,由Agent-RRM提供文本批评,Agent再根据批评意见进行二次修正。这类似于给模型配备了一个实时指导的老师。
2. Reagent-R(基于奖励的强化学习)
该模式将过程分直接引入强化学习的奖励函数中。训练不再仅仅依赖终局的对错信号,而是将“结果奖励 + 过程分数”进行加权。这极大缓解了长链任务中的奖励稀疏问题,让模型在每一步探索中都能获得反馈。
3. Reagent-U(统一反馈训练)
这是Reagent框架的最强形态。它将文本批评和过程奖励深度融合进同一个训练循环中。模型不仅要学习如何第一次就做对,还要学习在收到批评后如何聪明地修正答案。最终部署时,Reagent-U不再需要外部评审器,因为“老师的教诲”已经通过训练内化到了模型参数中。
实验数据:8B模型逆袭大参数模型的秘密
在多项严苛的基准测试中,Reagent框架展现了惊人的潜力。在 GAIA(通用人工智能助手基准)的文本子集上,基于8B参数规模的小模型在经过Reagent-U训练后,平均成绩达到了43.7%。这一表现不仅大幅超越了传统的训练方法,甚至在部分指标上追平或超过了参数量更大的开源Agent模型。
此外,在WebWalkerQA、HLE等涉及复杂网页导航和跨工具协作的场景下,Reagent框架下的模型表现更加稳健。它不再容易被“瞎蒙”的成功带偏,而是展现出了极强的逻辑一致性。
结论与未来展望
港中文与美团的这项研究证明了:细粒度的过程反馈是提升Agent智能的关键。通过将“思考过程”量化并转化为可学习的信号,我们能够让参数量较小的模型也具备处理复杂长链任务的能力。
对于广大的 人工智能 开发者和 AI变现 从业者来说,Reagent框架提供了一个清晰的思路:与其盲目追求模型规模,不如在训练数据的反馈质量上下功夫。随着 chatGPT、claude 等大模型的持续演进,如何让Agent更像人类一样思考和反思,将是通往 AGI 的必经之路。
持续关注 AI日报,掌握 openai 及全球顶尖实验室的最新科研成果,探索大模型时代的无限可能。
Loading...