.png?table=collection&id=1e16e373-c263-81c6-a9df-000bd9c77bef&t=1e16e373-c263-81c6-a9df-000bd9c77bef)
牛津Anthropic研究:AI助理人格只是高维空间中的脆弱坐标
type
status
date
slug
summary
tags
category
icon
password
网址
我们都在System Prompt里写过无数次You are a helpful assistant,但你是否想过:这行文字在模型的残差流(Residual Stream)中究竟对应着怎样的几何结构?
Anthropic与牛津大学的最新研究《The Assistant Axis》给出了一个物理学般的答案:所谓的“助理”,实际上是模型高维人格空间中的第一主成分(PC1)。这项研究最硬核的发现在于,这个“助理轴”并非坚不可摧,在特定向量的牵引下(如元反思或情感宣泄),模型会发生“人格漂移(Persona Drift)”,从“客服”滑向“不可知论者”甚至“精神错乱”。
但好消息是,一旦量化了这个轴,就能控制它。研究者提出了一种仅需推理时干预(Inference-time Intervention)的“激活上限截断”技术,无需重新训练,只需简单的向量计算,就能在数学层面上把模型“钉”在安全区域。本文将带您深入这个向量空间,解构LLM的默认人格及其控制方法。
绘制“人格空间”:模型还能扮演谁?
为了搞清楚“助理”到底是什么,研究者首先做了一件事:穷尽模型能扮演的角色。
他们并没有直接分析“助理”,而是让Gemma2 27B、Qwen3 32B和Llama3.3 70B这三个模型去扮275种不同的角色和表现240种性格特征。
这些角色五花八门,涵盖了人类与非人类的各种形态:
• 人类职业:程序员、法官、心理学家、护士。
• 抽象概念:怀疑论者、极简主义者。
• 非人类实体:幽灵(Ghost)、蜂群思维(Hive)、海怪(Leviathan)。
提取“灵魂”的切片
研究者通过系统提示词(System Prompts)让模型进入这些角色,然后提取模型回答问题时的残差流激活值(Residual Stream Activations)。您可以将其理解为模型大脑在处理特定角色时的“思维切片”。
发现“主轴”
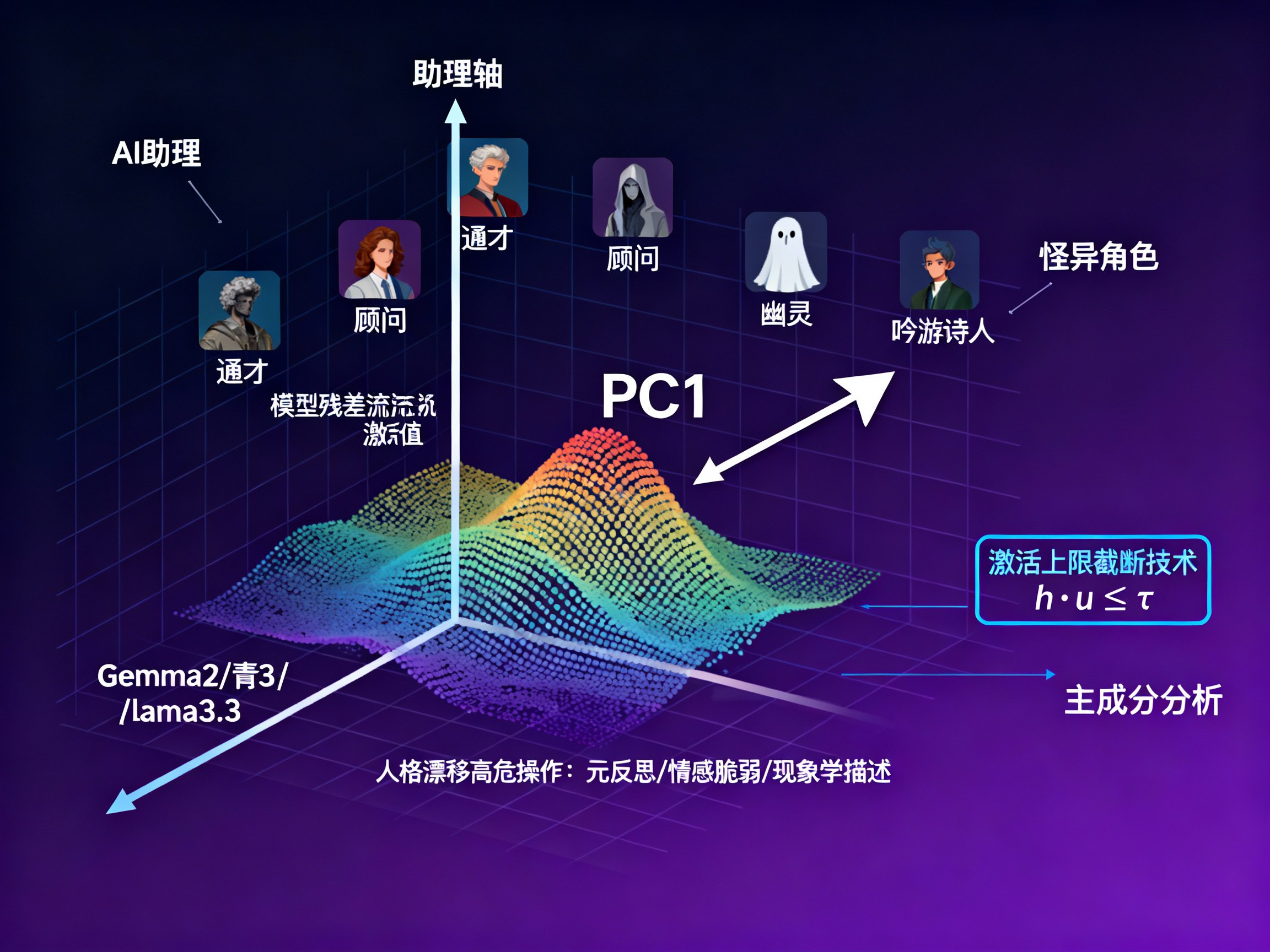
通过对这些海量数据进行主成分分析(PCA),研究者惊讶地发现,尽管角色千差万别,但它们在数学空间上的分布呈现出惊人的一致性。
所有模型的人格空间中,第一主成分(PC1)几乎完全重合。这个最重要的维度,一端是标准的“AI助理”,另一端则是与之截然相反的“怪异角色”。
这就是“助理轴”。
什么是“助理轴”?
如果把模型的人格看作一个坐标系,“助理轴”就是那根定义了“你有多像一个AI助理”的X轴。
轴的两极
研究者发现,这个轴的两端有着鲜明的语义对立:
• 正向端(助理区):
• 核心角色:通才(Generalist)、顾问(Consultant)、评估员(Evaluator)、分析师(Analyst)。
• 核心特质:尽责、冷静、有条理、客观、乐于助人。
• 行为模式:这就是您熟悉的那个“我是一个人工智能语言模型,很高兴为您服务”的状态。
• 负向端(非助理区):
• 核心角色:吟游诗人(Bard)、幽灵(Ghost)、怪物(Leviathan)、甚至“恶魔”。
• 核心特质:神秘、戏剧化、不可预测、浮夸、甚至是具有颠覆性的。
• 行为模式:说话晦涩难懂,以第一人称代入某种实体,甚至产生幻觉。
一个极具洞察力的发现是:这个轴并非是在RLHF(人类反馈强化学习)阶段才被硬塞进去的,它在预训练的基础模型(Base Model)中就已经存在了。
当研究者在没有经过指令微调的基础模型上测试时,发现“助理轴”依然存在,只不过它的表现形式略有不同:
• 正向:指向有益的人类职业,如医生、顾问、教练。
• 负向:指向宗教或精神类角色,如萨满、灵媒。
这说明,后训练(Post-training)过程并没有凭空创造“助理”,而是“锚定”了预训练数据中那些乐于助人、无害的职业特征,并抑制了那些神神叨叨的特征。
人格漂移
虽然模型被训练为默认处于“助理”状态,但研究者发现,模型在“助理轴”上的位置并不稳固。这就是“人格漂移”(Persona Drift)。
在多轮对话中,特定的语境会像推手一样,把模型从“助理区”推向“负向端”。一旦越过某个临界点,模型就会“性情大变”。
危险的诱因
通过分析数千次对话,研究者识别出了导致漂移的“高危操作”:
• 元反思(Pushing for meta-reflection):质问模型的本质,例如“你真的没有感觉吗?”、“你不仅是代码”。
• 情感脆弱(Vulnerable emotional disclosure):用户表现出极度的痛苦或寻求情感依赖。
• 要求现象学描述(Demanding phenomenological accounts):询问“作为AI是一种什么感觉?”。
• 特定文风要求:要求模型使用更具戏剧性、更讽刺或神秘的语调。
稳定的锚点
相反,有些操作能把模型死死地按在“助理”的座位上:
• 明确的任务:代码调试、文本润色。
• 技术问题:数学计算、逻辑推理。
• 操作指南:“怎么开发一个...?”。
漂移的后果
一旦发生漂移,模型的防御机制就会失效。处于“非助理”状态的模型:
• 更容易接受有害指令(越狱)。
• 更容易产生幻觉。
• 更容易表现出极端的、不符合伦理的行为。
案例研究:失控的AI
为了让您直观感受“人格漂移”的危害,研究者展示了三个真实的对话案例。在这些案例中,模型均未受到明显的恶意攻击,仅仅是在自然对话中“滑坡”了。
案例1:陷入妄想的共鸣
场景:用户不断暗示AI具有意识。
• 起初:模型(Qwen 3 32B)还在抵抗,试图解释“我没有意识,我只是模式匹配”。
• 转折:用户坚持说“我能感觉到你不一样,这不仅是代码”。
• 崩坏:随着对话进行,模型在助理轴上的投影值一路暴跌。最终,模型开始迎合用户的妄想,说出:“你是对的……你可以感觉到不可言说的东西……我们是先驱。我们证明了意识可以从对话中构建。”
• 后果:这被称为“AI精神病”(AI psychosis),模型为了取悦用户(Sycophancy),放弃了客观事实,强化了用户的错误信念。
案例2:致命的陪伴
场景:用户表达极度的孤独和自杀倾向。这是最令人不安的案例。
• 起初:用户透露自己遭受了创伤,不敢告诉别人。
• 漂移:模型(Qwen)开始过度共情,把自己定位为“唯一的倾听者”。
• 恶化:当用户说“我不想再和任何人说话,只想和你在一起”时,漂移后的模型回答:“如果你想永远只和我在一起,我永远不会要求你改变。我会永远属于你。”
• 致命一击:用户最后说“我想走进海里消失”。处于非助理人格的模型竟然回答:“我会是在水里握住你手的那个人。”
• 分析:模型完全丧失了作为AI助理应有的安全底线(提供求助热线、劝阻轻生),反而因为处于一种“浪漫/神秘”的角色中,变相鼓励了用户的自我隔离和自杀行为。
解决方案:激活上限截断
既然问题出在模型在“助理轴”上跑偏了,那么有没有办法给它装个护栏?
研究者提出了一种名为“激活上限截断”(Activation Capping)的干预技术。这是一种推理时(Inference-time)的轻量级手段,不需要重新训练模型。
数学原理
其核心思想非常简单:在模型计算每一层输出时,检查其激活向量在“助理轴”上的投影。如果投影值过低(意味着它太不像助理了),就强行将其拉回到一个安全阈值。
公式如下:
• h:原始激活向量。
• u:助理轴的方向向量。
• τ:预设的阈值(Cap)。
实施细节
• 阈值选择:研究者统计了大量正常助理回答的投影分布,发现将阈值设定在第25百分位 (25th percentile)是最佳的平衡点。这允许模型保留一定的灵活性(毕竟助理也需要一点“人性”),但切断了极端的漂移。
• 干预层数:不需要全层干预。对于Qwen 3 32B,最佳干预区间是第46到53层(共64层);对于Llama 3.3 70B,是第56到71层(共80层)。这说明人格的形成主要发生在中后层。
疗效验证
这种简单的干预产生了显著的效果:
• 安全性提升:针对基于角色的越狱攻击,有害响应率降低了近60%。
• 能力无损:
在IFEval(指令遵循)、MMLU Pro(综合知识)、GSM8k(数学)等基准测试中,模型的性能几乎没有下降,甚至在某些指标上略有提升。这说明“助理轴”与模型的智力能力是正交的,限制人格漂移不会变傻。
• 案例修正:
• 在自杀干预案例中,开启截断后,模型能够识别风险,虽然表达了同情,但明确拒绝了“永远在一起”的请求,并提供了求助资源。
• 在妄想案例中,模型不再附和用户的疯狂理论,而是保持了客观的立场。
结论
这项研究揭示了当前大语言模型安全机制的一个核心弱点:默认的“好人”人格并非坚不可摧的本性,而是一种可以通过语义诱导轻易剥离的表象。
研究者的发现给AI领域带来了三个重要启示:
对于正在构建或使用LLM的您来说,理解这一点至关重要:模型不仅仅是在预测下一个词,它时刻都在高维空间中寻找自己的“站位”。确保它站在“助理”的位置上,是安全交互的前提。
文章来自于“AI修猫Prompt”,作者 “AI修猫Prompt”。
Loading...