.png?table=collection&id=1e16e373-c263-81c6-a9df-000bd9c77bef&t=1e16e373-c263-81c6-a9df-000bd9c77bef)
AAAI 2026新作:AdaptCLIP零样本横扫12个工业医疗数据集
type
status
date
slug
summary
tags
category
icon
password
网址
视觉模型用于工业“缺陷检测”等领域已经相对成熟,但当前普遍使用的传统模型在训练时对数据要求较高,需要大量的经过精细标注的数据才能训练出理想效果。
而大模型有望在“零样本/少样本识别”条件下达到与传统模型相当的性能。
CLIP是一个全球比较有名的开源视觉-语言基础模型,由OpenAI在2021年发布。本研究则在此基础上优化模型性能,使其在工业质检与医学影像等复杂真实场景中得以快速上手胜任工作。
在工业质检与医学影像等真实场景中,异常检测始终面临一个核心矛盾:
模型既要跨领域泛化,又要在几乎没有目标域数据的情况下,精确定位细微异常。
现实生产中,产线频繁换型,新产品刚投产,缺陷样本极少,而异常往往表现为局部、稀疏、小尺度的像素级变化。这使得大量依赖监督学习或目标域微调的方法难以真正落地。
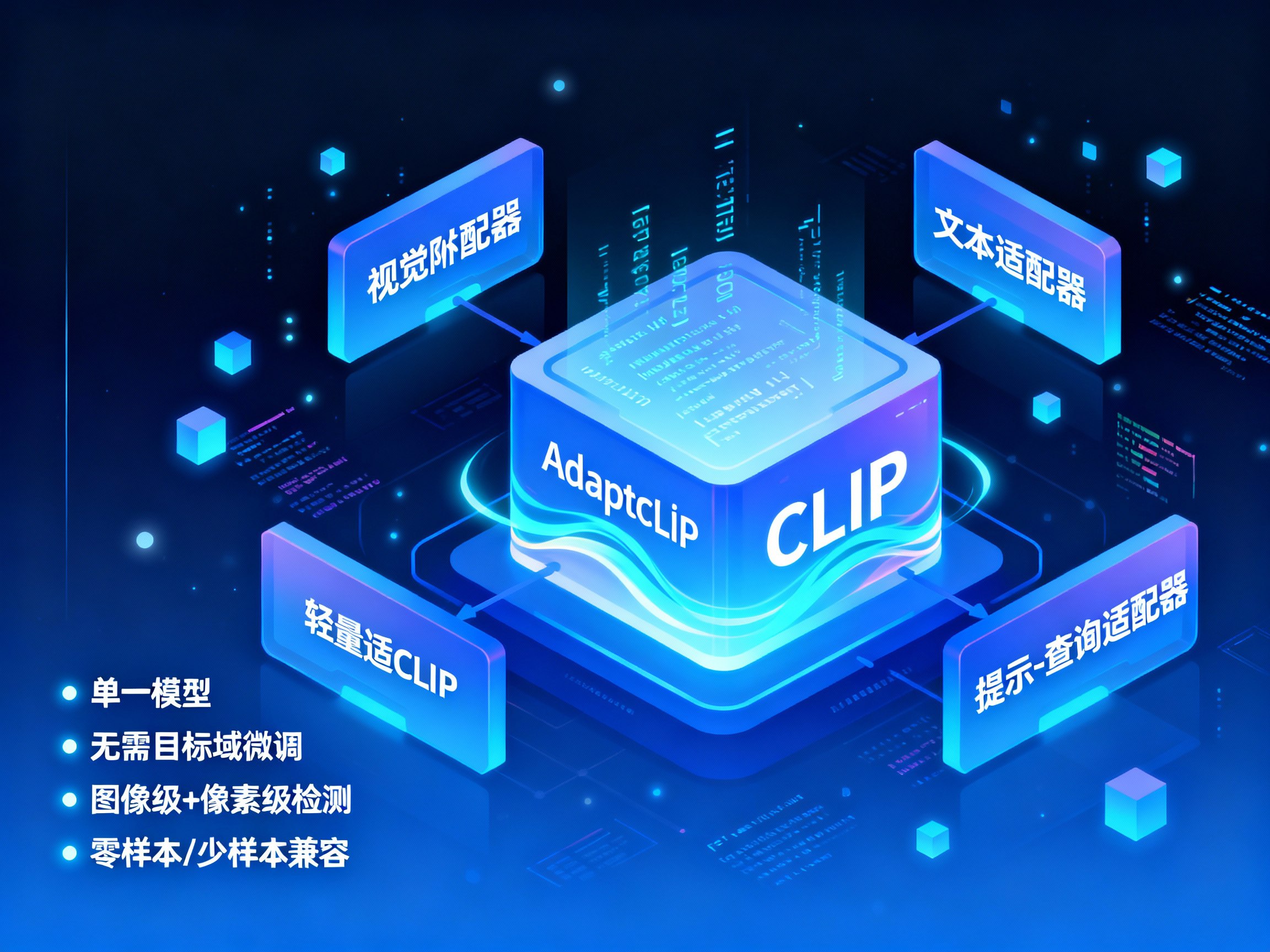
近日,西门子与腾讯优图联合研究团队提出AdaptCLIP,一种通用视觉异常检测框架,具有以下亮点:
• 单一模型
• 无需目标域微调
• 同时支持图像级异常分类+像素级异常分割
• 兼容零样本/少样本推理
一、为什么“通用异常检测”一直做不好?
通用异常检测要求模型在训练域与测试域分布显著不同的前提下,仍能稳定检测异常。这一设定暴露了现有方法的结构性瓶颈:
传统无监督AD方法(如PaDiM、PatchCore、重建式模型)依赖大量正常样本,一旦面对未见类别或新领域,性能迅速退化。
CLIP驱动的方法虽借助跨模态先验实现零样本检测,但代价并不小:
• WinCLIP依赖密集窗口扫描,计算与显存开销巨大;
• AnomalyCLIP、AdaCLIP通过修改中间层或引入复杂token,削弱了CLIP的原始表征能力;
• InCtrl、PromptAD要么只支持图像级判断,要么仍需目标域重新训练。
问题归结为一句话:
如何在不破坏CLIP原有泛化能力的前提下,让它真正学会“找异常”?
二、AdaptCLIP的答案:少即是多
AdaptCLIP将CLIP视为一种“基础服务模型”,不改动其主干结构,仅在输入与输出端引入三个轻量适配器:
• 视觉适配器(Visual Adapter)
• 文本适配器(Text Adapter)
• 提示-查询适配器(Prompt-Query Adapter)
并由两个关键洞见驱动:
- 视觉与文本表征不应联合学习,而应交替学习;
- 少样本对比学习不能只看残差,还必须结合上下文信息。
△ 图1 AdaptCLIP架构图
三、交替学习:零样本异常检测的核心机制
3.1从CLIP的异常判别说起
给定查询图像,CLIP视觉编码器输出局部patch token与全局图像token,并与“正常/异常”文本嵌入进行相似度比对,即可得到图像级异常分数与像素级异常图。
但在工业场景中,原生CLIP的像素级定位能力明显不足。
3.2视觉适配器:只做“微调”,不做“重塑”
视觉适配器分别作用于局部patch token与全局token,均采用残差MLP结构,对CLIP表征进行轻量自适应调整:
其中Fiq和fq分别表示CLIP输出的局部patch token和全局图像token,θvl和θvg为适配器可学习参数。
其目标是在固定文本语义空间的前提下,使视觉特征更贴合异常检测任务,从而显著提升像素级定位能力。
3.3文本适配器:抛弃prompt工程
文本适配器不再依赖人工设计的模板,而是直接学习“正常/异常”两类可优化提示嵌入,并输入冻结的CLIP文本编码器生成语义表示:
其中T(·)表示CLIP文本编码器,w’α和w’n为最终用于特征比对的异常与正常文本嵌入。
这一设计在保留CLIP原有语义结构的同时,降低了对prompt经验的依赖。
为什么交替学习优于联合学习?
论文通过消融实验发现,在小规模训练数据下,联合学习易过拟合。
因此AdaptCLIP采用交替优化策略:
固定文本→优化视觉;固定视觉→优化文本,循环迭代。
该策略在多个工业与医学数据集上,显著优于联合学习方案,成为零样本异常检测性能提升的关键。
四、对比学习:少样本场景下的关键补强
当可获得少量正常样本时,AdaptCLIP启用提示-查询适配器。
4.1空间对齐:先对齐,再比较
针对查询图像的每个patch,模型在正常样本中搜索欧氏距离最近的patch作为对齐目标,从而消除旋转、平移带来的干扰,并计算对齐残差特征。
4.2残差+上下文:避免“只见树木,不见森林”
论文发现,仅依赖残差特征虽然能突出差异,但容易引入噪声、丢失上下文信息。
因此AdaptCLIP将原始查询特征与对齐残差逐元素相加,形成联合特征:
在1-shot设置下,引入上下文后,在MVTec数据集上的像素级AUPR提升约40%,成为少样本性能跃迁的关键因素。
4.3从联合特征到异常预测:极简分割与分类头
在得到融合了上下文与对齐残差的联合特征后,AdaptCLIP采用一套轻量输出头完成异常预测。
像素级分割:联合特征经1×1卷积与若干转置卷积模块上采样至原分辨率,生成异常图。
图像级分类:对联合特征进行平均池化与最大池化,融合后输入MLP输出异常分数。
推理阶段根据可用信息进行结果融合:
零样本:融合视觉适配器与文本适配器预测;少样本:在此基础上进一步融合提示-查询适配器结果。
五、实验结果:跨工业与医疗的一致验证
AdaptCLIP在12个公开基准数据集(8个工业+4个医疗)上进行了系统评估,覆盖不同成像模态与异常类型。
在零样本异常检测场景下,AdaptCLIP在MVTec、VisA、BTAD、Real-IAD等工业数据集上,图像级AUROC平均达到86.2%(SOTA),在多类未见产品与跨类别测试中依然保持稳定优势。
在医学影像任务中,AdaptCLIP在内窥镜数据集Kvasir与Endo的零样本像素级异常分割AUPR平均达到48.7%,并在Br35H(MRI)、COVID-19(X-ray)等数据集的零样本图像级异常检测中取得平均90.7%的AUROC,均显著高于其他现有方法。
在少样本设置下,随着正常样本数量从1-shot增加至4-shot,异常区域的定位逐步细化。提示-查询适配器显著降低了误报区域,使异常边界更加清晰。
从模型规模与效率来看,AdaptCLIP在零样本条件下仅引入约0.6M额外可训练参数(对比方法可高达10.7M)。在518×518分辨率下,零样本条件单张图像推理时间约162 ms,兼顾检测精度与实际部署需求。
△ 图2 AdaptCLIP在工业与医疗数据上检测结果可视化
△ 图3 AdaptCLIP在工业与医疗数据上图像级AUROC分类结果与其他方法对比
△ 图4 AdaptCLIP在工业与医疗数据上像素级AUPR分割结果与其他方法对比
△ 图5 AdaptCLIP与其他方法对比模型规模与效率
可迁移的异常检测
AdaptCLIP并未试图“重造一个更大的模型”,而是通过交替学习+轻量适配+上下文感知对比,在不破坏CLIP原始能力的前提下,实现了真正可迁移的异常检测。
它为工业与医疗等开放场景提供了一条清晰路径:
用最少的结构改动,换取最大的泛化收益。
论文链接:https://arxiv.org/abs/2505.09926
文章来自于“量子位”,作者 “AdaptCLIP团队”。
Loading...