.png?table=collection&id=1e16e373-c263-81c6-a9df-000bd9c77bef&t=1e16e373-c263-81c6-a9df-000bd9c77bef)
颠覆认知:NeurIPS满分论文揭示强化学习并非大模型推理上限的关键
type
status
date
slug
summary
tags
category
icon
password
网址
在人工智能(AI)领域,通往更强推理能力的道路似乎早已被指明,那就是以强化学习(RL)为核心的自我进化路径。从OpenAI到DeepSeek,各大顶尖机构纷纷将宝押在“可验证奖励的强化学习”(RLVR)上,认为这是让大模型(LLM)实现能力突破、逼近通用人工智能(AGI)的终极法门。然而,一篇来自清华大学和上海交通大学的论文,如同一道惊雷,撼动了这一主流共识。这篇在NeurIPS上获得所有审稿人满分评价的重磅研究指出:我们可能都高估了强化学习。
这项研究的核心观点极具颠覆性:真正决定大模型推理能力上限的,是其基础模型(Base Model)本身,而非后续的强化学习过程。 更有甚者,论文提出,知识蒸馏(Distillation)比强化学习在实现模型自我进化方面更具潜力。这一结论无疑给当前火热的RLVR研究泼了一盆冷水,并促使我们重新审视大模型能力提升的根本逻辑。想要紧跟这类前沿的AI资讯,可以访问AI门户网站 https://aigc.bar 获取最新动态。
惊人结论:强化学习的“神话”被打破?
长期以来,AI社区普遍存在一个假设:通过强化学习,特别是RLVR,大语言模型不仅能提升解决问题的效率,更能学会其基础模型原本不具备的全新推理路径,从而扩展其能力边界。简而言之,人们相信RL能让模型“变得更聪明”。
但这篇名为《Does Reinforcement Learning Really Incentivize Reasoning Capacity in LLMs Beyond the Base Model?》的论文,通过一系列严谨的实验得出了一个截然相反的结论:
- 强化而非发现:RLVR的主要作用是“强化”基础模型已有的推理路径,让模型更高效、更稳定地找到正确答案,而不是“发现”它闻所未闻的新解法。
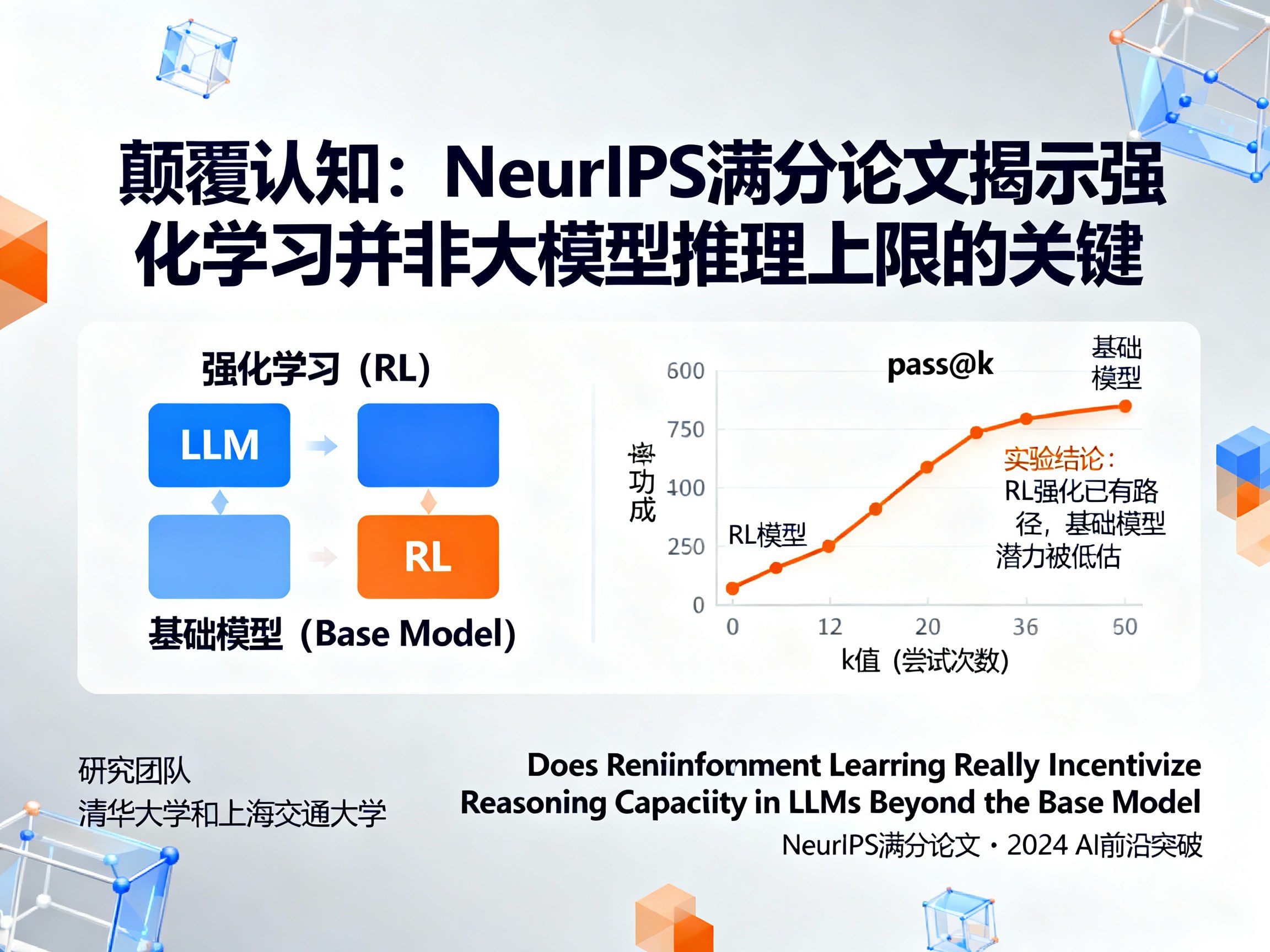
- 隐藏的潜力:在低强度尝试(如一次生成)中,RL训练后的模型表现更优。但随着尝试次数的增加,基础模型的成功率反而会追上甚至反超RL模型。这表明,基础模型本身蕴含着被低估的、更广阔的推理潜力,只是没有被高效地激发出来。
- 算法的局限:无论是PPO还是其他先进的RL算法,在提升采样效率上虽有作用,但距离理论上基础模型的“能力天花板”仍有显著差距。依靠RL来突破这个天花板,目前看来还远远不够。
这个结论意味着,当前围绕RLVR进行的大量投入,可能更多地是在做“优化”而非“进化”的工作。它让模型更会“考试”,而不是真正地“学习”新知识。
揭秘真相:pass@k指标下的深度洞察
为了得出上述颠覆性结论,研究团队采用了一个关键的评估指标——pass@k。
与只看单次生成结果的准确率不同,pass@k衡量的是模型在进行k次尝试后,至少有一次成功的概率。这个指标能够更精准地探测模型的“能力上限”(它到底能不能解决这个问题),而不是其“平均表现”(它通常能不能解决这个问题)。
打个比方,这就像评估一个学生的数学能力。传统指标是看他一次考试能得多少分,而pass@k则是让他做一道难题,允许他尝试k次,只要有一次做对,就认为他具备解决该问题的潜力。
研究团队在数学推理、代码生成和视觉推理三大领域的权威数据集上,对Qwen2.5、LLaMA-3.1等主流基础模型及其经过多种RL算法训练后的版本进行了对比测试。实验结果清晰地描绘出两条不同的曲线:
1. 在k值较小(如pass@1)时,RL模型的曲线更高,说明它能更快地给出正确答案。
2. 随着k值增大(如pass@256, pass@1024),基础模型的曲线逐渐攀升,最终与RL模型持平甚至超越。
这有力地证明了,RL更像一个高效的“搜索策略优化器”,它教会模型如何在其已有的知识库中快速定位最优解,但并未扩充这个知识库本身。
新的希望:为何蒸馏比强化学习更有潜力?
如果强化学习不是突破口,那么通往更强人工智能的道路在何方?论文给出了一个明确的方向:知识蒸馏。
两者的根本区别在于信息来源:
* 强化学习:本质上是一种“向内求索”。模型通过自我试错和奖励反馈来调整策略,但其所有探索都局限于基础模型固有的能力范围之内。它无法凭空创造出自己知识体系之外的推理模式。
* 知识蒸馏:则是一种“向外学习”。它通过让一个“学生”模型学习一个更强大的“教师”模型的输出,从而直接吸收教师模型独特的、可能更高级的推理模式。这是一种外部知识的注入,能够真正地帮助学生模型突破自身局限,学会新的思维方式。
因此,研究团队认为,蒸馏更有可能“扩展”模型的推理能力边界,因为它为模型打开了一扇通往新知识和新方法的大门。这对于未来大模型的发展,乃至ChatGPT、Claude等产品的迭代都具有重要的指导意义。
结论:重新审视大模型的进化之路
这篇来自清华和上交团队的NeurIPS满分论文,无疑是2024年AI新闻领域最具影响力的研究之一。它并非要全盘否定强化学习的价值——在提升模型输出效率和稳定性方面,RL依然是极其强大的工具。
然而,它深刻地提醒我们,必须清晰地区分“优化现有能力”与“扩展能力边界”。将强化学习视为通往更强推理能力的唯一或最佳路径,可能是一种误解。未来的研究或许需要将更多目光投向知识蒸馏等能够引入外部新知的范式上。
这项研究不仅展现了中国顶尖学府在前沿AI理论探索上的强大实力,也为全球的LLM开发者和研究者指明了一个值得深思的新方向。在通往AGI的征途上,每一次这样的深刻洞察,都是推动整个领域向前迈进的关键一步。想要获取更多关于AI的深度分析和前沿AI资讯,欢迎访问 https://aigc.bar。
Loading...